Robust Forward model selection using Cp
In the selection of regression variables is estimated from a large regression model with n \times p^+ matrix X^+, p^+ > p, of which X is submatrix. The unbiased estimator of \sigma^2 comes from regression on all p^+ columns of X^+ and can be written
s^2=R_{p^+}(n)/(n-p^+)
C_p is defined as follows:
C_p = R_p(n)/s^2 - n+2p=(n-p^+)R_p(n)/R_{p^+}(n)-n+2p.
One derivation of C_p (Mallows 1973) is that it provides an estimate of the mean squared error of prediction at the n observational points from the model with p linear parameters, provided the full model with p^+ parameters yields an unbiased estimate of \sigma^2. Then E\{R_p(n)\} = (n − p)\sigma^2, E(s^2) = \sigma^2 and E(C_p) is approximately p.
The C_p criterion for all observations is a function of the residual sums of squares R_{p}(n) and R_{p^+}(n). For a subset of m observations we can define the forward value of C_p (which we denote C_p(m)) as
C_p(m)= (m-p^+)R_p(m)/R_{p^+}(m)-m+2p.
For each m we calculate C_p(m) for all models of interest. However, some care is needed in interpreting this definition. For each of the models with p parameters, the search may be different, so that the subset S(m) will depend on which model is being fitted. This same subset is used to calculate R_{p^+}(n), so that the estimate s^2 will also depend on the particular model being evaluated as well as on m. Since the searches are for different models, outliers will not necessarily enter in the same order for all models.
It is straightforward to show that the distribution of C_p is
C_p \sim (p^+ -p)F+2p-p^+ \quad \quad \textrm{where}\quad \quad F \sim F_{p^+-p,n-p^+}. Riani and Atkinson (2010) show that when we consider a subset of size m, the full sample distribution holds with n replaced by m. More specifically: C_p(m) \sim (p^+ -p)F+2p-p^+ \quad \quad \textrm{where}\quad \quad F \sim F_{p^+-p,m-p^+}.so that the only change is in the degrees of freedom of the F distribution
The expression of C_p(m) is the multivariate generalization of the forward added variable t test of Atkinson and Riani (2002). The orthogonality of the distribution to the search can again be shown by the orthogonality of the residuals of added variables. The difference is that now the adjustments using the variables are not restricted to the addition of single terms to the model. It is important to be clear about the similarity of the structure of the forward searches in the two situations. In the calculation of added variable t tests a single search is used for each model and the added variable statistic constructed. Likewise, in the calculation of C_p(m) , there is a single search for each model which is used for the calculation of the two sums of squares R_p(m) and R_{p^+}(m) . As a consequence the distributional results for C_p(m) are a direct multivariate generalization of those for the t test.
Example 1
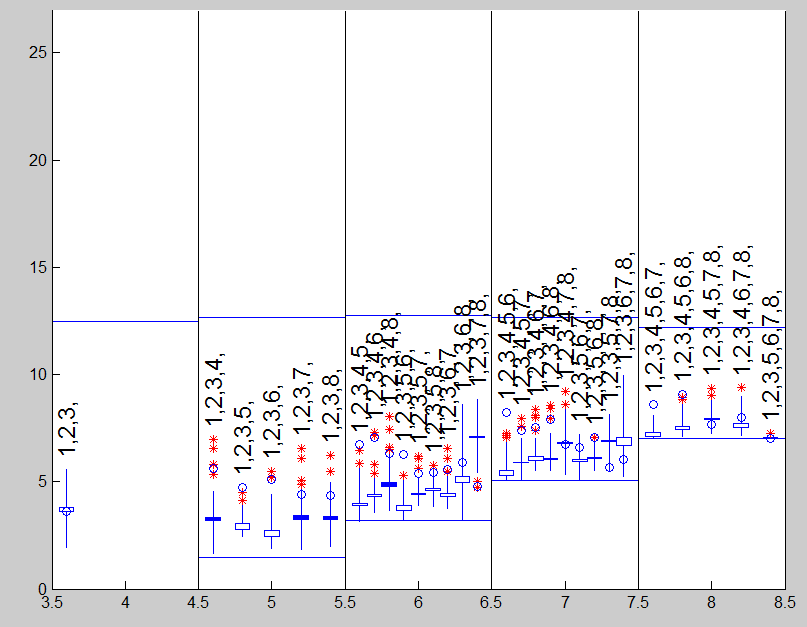
In the analysis we use hospital data which had already been used in section Robust Forward Variable Selection using Added t tests. We add other four noise variables to X and perform model selection.
load('hospitalFS.txt');
y1=hospitalFS(:,5);
X=hospitalFS(:,1:4);
% Compute forward added T tests
out=FSRms(y1,[X rand(size(X))],'plots',1)
The candlestick plot shows that the bet model is the one which contains the first 3 explanatory variables.
| Functions |
• The developers of the toolbox• The forward search group • Terms of Use• Acknowledgments