
|
quickselectFS |
quickselectFSw |
 |
quickselectFS_demo
quickselectFS_demo illustrates the functioning of quickselectFS
Description
Examples
 quickselectFS_demo with all default options.
quickselectFS_demo with all default options.
quickselectFS_demo with all default options.
rng('default');
rng(12345);
n=15;
Y=1:n; Y=shuffling(Y);
k=7;
[out]=quickselectFS_demo(Y,k);
% Check the result
sorY=sort(Y);
disp([out,sorY(k)])
7 7
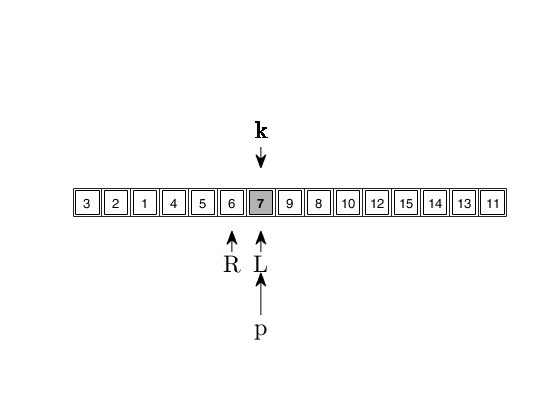
Input Arguments
Output Arguments
References
Azzini, I., Perrotta, D. and Torti, F. (2023), A practically efficient fixed-pivot selection algorithm and its extensible MATLAB suite, "arXiv, stat.ME, eprint 2302.05705"