A vector with n elements that contains the response variables.
Missing values (NaN's) and infinite values (Inf's) are
allowed, since observations (rows) with missing or infinite
values will automatically be excluded from the
computations.
Data Types: single| double
Data matrix of explanatory variables (also called
'regressors') of dimension (n x (bigP-1)).
The intercept will be added in an automatic way, so that the
dimension of the full model is bigP.
Rows of X represent observations, and columns represent
variables. Missing values (NaN's) and infinite values
(Inf's) are allowed, since observations (rows) with missing
or infinite values will automatically be excluded from the
computations.
Data Types: single| double
Specify optional comma-separated pairs of Name,Value arguments.
Name is the argument name and Value
is the corresponding value. Name must appear
inside single quotes (' ').
You can specify several name and value pair arguments in any order as
Name1,Value1,...,NameN,ValueN.
Example:
'intercept',false
, 'init',100 starts monitoring from step m=100
, 'h',round(n*0,75)
, 'nsamp',1000
, 'lms',1
, 'nocheck',true
, 'smallpint',3
, 'labels',{'1','2'}
, 'fin_step',[1 50]
, 'first_k',5
, 'ignore',1
, 'ExclThresh',0.9
, 'meanmed',1
, 'plots',1
, 'rl',0.3
, 'quant',[0.01;0.99]
, 'CandleWidth',0.01
, 'LineWidth',0.01
, 'ylimy',[0 10]
, 'xlimy',[0 10]
Indicator for the constant term (intercept) in the fit,
specified as the comma-separated pair consisting of
'Intercept' and either true to include or false to remove
the constant term from the model.
Example: 'intercept',false
Data Types: boolean
It specifies the initial subset size to start
monitoring the required quantities, if
init is not specified it set equal to:
p+1, if the sample size is smaller than 40;
min(3*p+1,floor(0.5*(n+p+1))), otherwise.
Example: 'init',100 starts monitoring from step m=100
Data Types: double
h is an integer greater or
equal than [(n+p+1)/2] but smaller then n
Example: 'h',round(n*0,75)
Data Types: double
Number of subsamples which will be extracted to find the
robust estimator. If nsamp=0, all subsets will be extracted.
They will be (n choose smallp).
Remark. If the number of all possible subset is <1000 the
default is to extract all subsets otherwise just 1000.
Example: 'nsamp',1000
Data Types: double
If lms=1 (default) Least Median of Squares is
computed, else Least Trimmed of Squares is computed.
Example: 'lms',1
Data Types: double
If nocheck is equal to true, no check is performed on
matrix y and matrix X. Note that y and X are left
unchanged. In other words, the additional column of ones
for the intercept is not added. As default nocheck=false.
Example: 'nocheck',true
Data Types: boolean
It specifies which submodels
(number of variables) must be considered.
The default is to consider all models
from size 2 to size bigP-1. In other words, as default,
smallpint=(bigP-1):-1:2.
When smallpint=2 all submodels including one explanatory
variable and the constant will be considered.
When smallpint=3 all submodels including two explanatory
variables and a constant will be considered. ....
Example: 'smallpint',3
Data Types: double
Cell array of strings of length bigP-1 containing the
names of the explanatory variables.
If labels is a missing
value, the following sequence of strings will be
automatically created for labelling the column of matrix X
(1,2,3,4,5,6,7,8,9,A,B,C,D,E,E,G,H,I,J,K,...,Z)
Example: 'labels',{'1','2'}
Data Types: cell
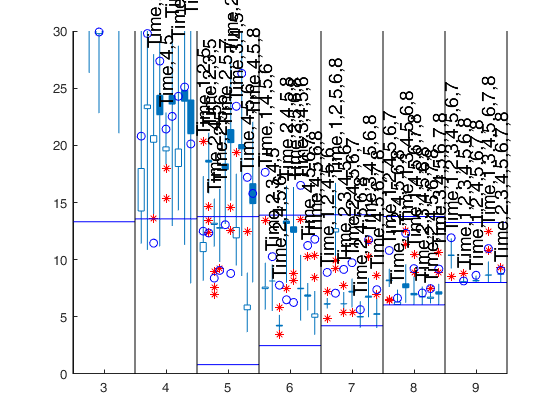
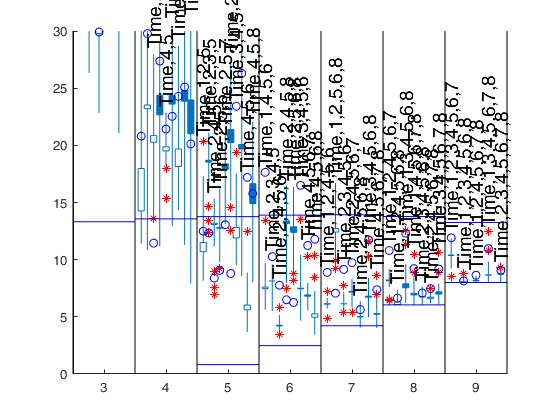
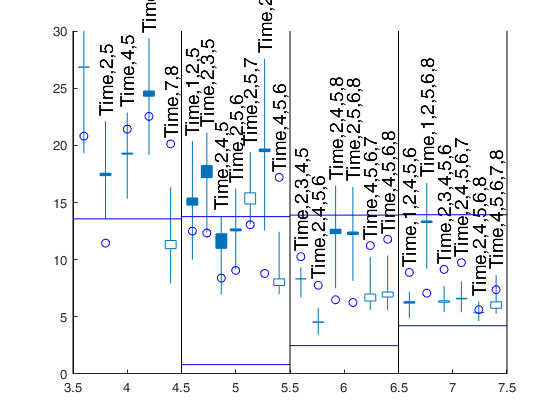
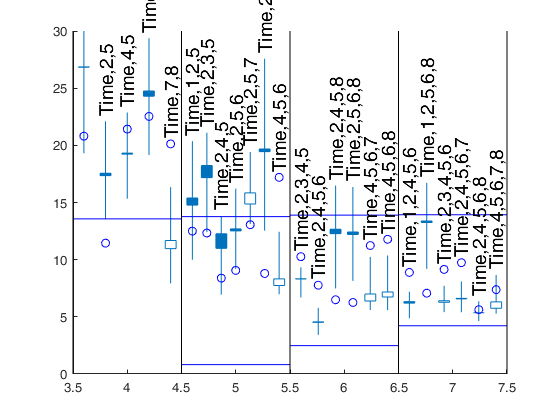
Initial and final step of the search which has to be
monitored to choose the best models as specified in scalar
first_k.
The first element of the vector specifies the initial step of the search
which has to be monitored to choose the best models as
specified in scalar first_k below. The second element
specifies the ending point of the central part of the
search. This information will be used to create the
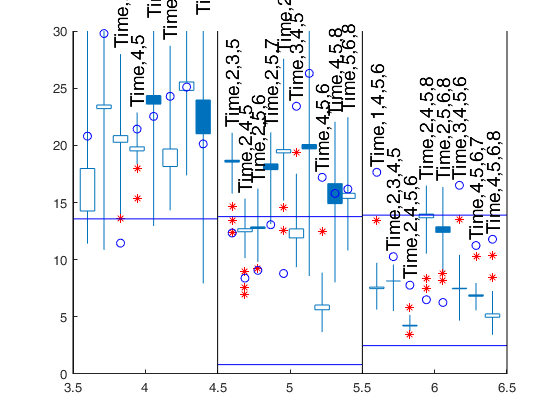
candlestick Cp plot.
If the elements of fin_step are integers greater or equal 1
they refer to the number of steps. For example, if
fin_step=[10 3] the program considers the last 10 steps to
choose the best models and the central part of the search
is defined up to step n-3.
If the elements of fin_step are real numbers
alpha (0<alpha<0.5) in the interval (0 0.5] then the
program considers the last round(n*alpha) steps.
As default fin_step(1)=round(n*0.2) that is the last 20%
of the steps are considered.
As default fin_step(2)=round(n*0.05) that
is the central part of the search extends up to 95% of the
observations
Example: 'fin_step',[1 50]
Data Types: double
Number of best models to
consider in each of the last fin_step.
For example, if
first_k=5 in each of the fin_step the models which had
the 5 smallest values of Cp are considered. As default
first_k=3
Example: 'first_k',5
Data Types: double
If ignore=1, when dealing with p explanatory
variables, the submodels of the models with p+1
explanatory variables which were considered irrelevant
according to option ExclThresh, are not considered. As
default ignore=1, because this saves computational time.
If ignore is different from 1, for each p all submodels of
size p which contain a constant are considered
Example: 'ignore',1
Data Types: double
It has effect only if ignore=1.
Exclusion threshold associated to the upper
percentage point of the F distribution of Cp which defines
the threshold for each p declaring models as irrelevant.
The default value of ExclThresh is 0.99999 that is the
models whose minimum value of Cp in the part of the
search defined by fin_step is above ExclThresh are
stored for each p. If option ignore=1, the submodels with
p-1 explanatory variables which are contained inside the
models considered irrelevant are not considered
Example: 'ExclThresh',0.9
Data Types: double
It specifies how to construct
the boxes of the candles.
If meanmed=1, boxes are constructed using mean and median,
else using the first and third quartile.
Example: 'meanmed',1
Data Types: double
If plot==1, a candlestick Cp plot is created on the screen
else (default) no plot is shown on the screen.
The options below only work when plots=1
Example: 'plots',1
Data Types: double
For example, if rl=0.4 for each smallp candles are spread in the
interval [smallp-rl smallp+rl]. The default value of rl
is 0.4. rl does not have to be greater than 0.45 otherwise
the candles overlap
Example: 'rl',0.3
Data Types: double
The default is to plot 2.5% and
97.5% envelopes. In other words the default is
quant=[0.025;0.975];
Example: 'quant',[0.01;0.99]
Data Types: double
The default width is 0.05;
Example: 'CandleWidth',0.01
Data Types: double
The default LineWidth is 0.5 points.
Example: 'LineWidth',0.01
Data Types: double
Default value is [-2 50] (automatic scale)
Example: 'ylimy',[0 10]
Data Types: double
Default value is '' (automatic scale)
Example: 'xlimy',[0 10]
Data Types: double
 FSRms with optional arguments.
FSRms with optional arguments.