mdTEM
mdTEM EM algorithm with trimming (TEM) for data with missing values.
Description
The algorithm:
- At each iteration compute adjusted partial Mahalanobis distances;
- Rank them and set weights w_i = 1 for the lowest n*(1-alpha) rows, else 0;
- Run E-step and M-step using these weights;
- Repeat until convergence or maxiter.
Example of use of option condmeanimp.out
=mdTEM(Y,
Name, Value)
Examples
 Example of use of option condmeanimp.
Example of use of option condmeanimp.
Example of use of option condmeanimp.number of variables
p = 15;
% number of observations
n = 1000;
% target pairwise correlation (0<rho<1)
rho = 0.9;
% Covariance matrix (unit variances)
Sigma = (1-rho)*eye(p) + rho*ones(p);
R = chol(Sigma); % upper-triangular such that Sigma = R'*R
% Generate samples ~ N(0,Sigma)
Yfull = randn(n,p) * R; % Strong positive correlation between the vars
missRate = 0.25; % MCAR missing probability per entry
missMask = rand(n,p) < missRate;
Y=Yfull;
Y(missMask) = NaN;
% md with missing imputation
out=mdTEM(Y,'condmeanimp',true);
% Mahalanobis distances using original matrix
d2Ori=mahalFS(Yfull,mean(Yfull),cov(Yfull));
% Calculate the Mahalanobis distance for the imputed data
d2Imp = mahalFS(out.Yimp, mean(out.Yimp), cov(out.Yimp));
% Compare original with distances for the imputed data
% Calculate the differences between original and imputed Mahalanobis distances
scatter(d2Ori,d2Imp)
% Add axis labels
xlabel('Original Mahalanobis Distances');
ylabel('Imputed Mahalanobis Distances');
grid on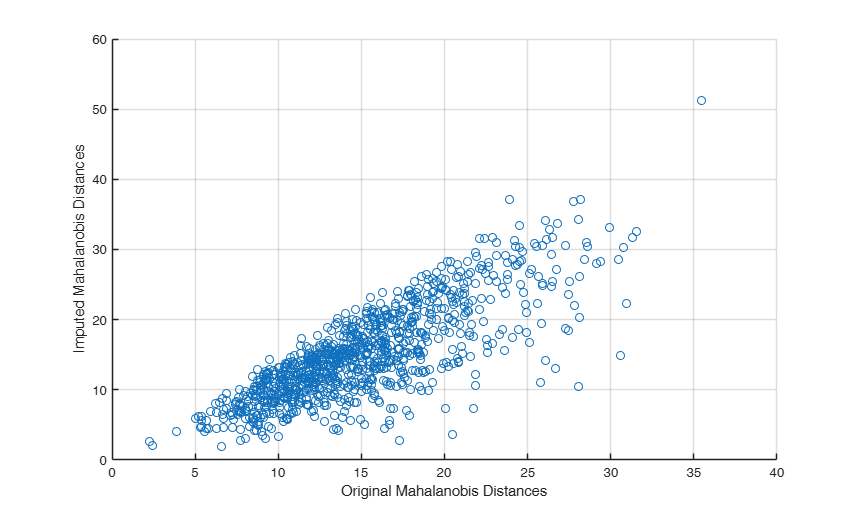
Input Arguments
Output Arguments
References
Little, R. J. A., & Rubin, D. B. (2019). Statistical Analysis with Missing Data (3rd ed.). Hoboken, NJ: John Wiley & Sons.
Templ, M. (2023). Visualization and Imputation of Missing Values: With Applications in R. Cham, Switzerland: Springer Nature.