ClusterRelabel
ClusterRelabel enables to control the labels of the clusters which contain predefined units
Syntax
Description
Start with labelling produced by tclustIC and produce consistent labels.IDXrelabelled
=ClusterRelabel(IDX,
pivotunits)
[
Example with detailed description of output element OldAndNewIndexes.IDXrelabelled,
idxMapping]
=ClusterRelabel(___)
Examples
 Example with detailed description of output element OldAndNewIndexes.
Example with detailed description of output element OldAndNewIndexes.
Example with detailed description of output element OldAndNewIndexes.Random seed to be example ro replicate the results.
rng(1000)
Y=load('geyser2.txt');
k=3;
[out]=tclust(Y,k,0.10,10);
% Make sure that group which contains
% unit 10 is always labelled with number 1. Similarly,
% make sure that the group which contains unit 12 is always labelled
% with number 2,
UnitsSameGroup=[10;12];
[idxnew, OldNewIndexes]=ClusterRelabel({out.idx}, UnitsSameGroup);
% In this case OldNewIndexes is equal to
% 3 1
% 3 2
% It means that in the first iteration labels 1 and 3 have swapped
% while in the second iteration label 3 and 2 have swapped
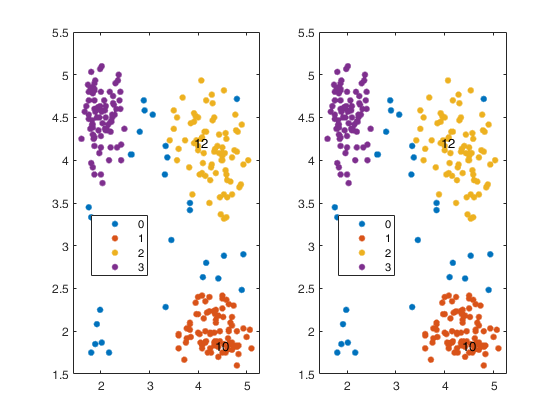
subplot(1,2,1)
gscatter(Y(:,1),Y(:,2),out.idx)
text(Y(UnitsSameGroup,1),Y(UnitsSameGroup,2),num2str(UnitsSameGroup))
subplot(1,2,2)
gscatter(Y(:,1),Y(:,2),idxnew{:})
text(Y(UnitsSameGroup,1),Y(UnitsSameGroup,2),num2str(UnitsSameGroup))
% Now (as is evident from the right panel) unit which contains group 10
% has label '1' while group which contains unit 12 has label '2'.
ClaLik with untrimmed units selected using crisp criterion Total estimated time to complete tclust: 0.77 seconds
Input Arguments
Output Arguments
References
Cerioli, A., Garcia-Escudero, L.A., Mayo-Iscar, A. and Riani M. (2017), Finding the Number of Groups in Model-Based Clustering via Constrained Likelihoods, "Journal of Computational and Graphical Statistics", pp. 404-416, https://doi.org/10.1080/10618600.2017.1390469