mveeda
mveeda monitors Minimum volume ellipsoid for a series of values of bdp
Syntax
Description
Examples
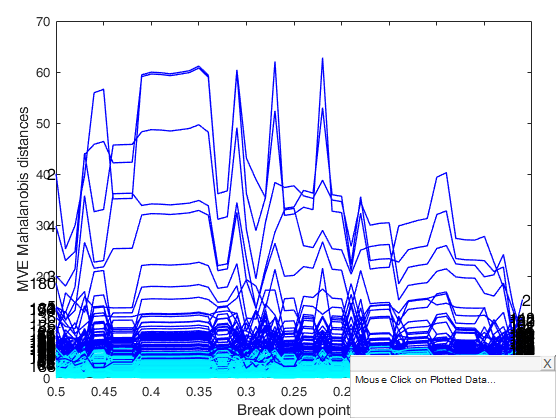
 mve monitoring with varargout.
mve monitoring with varargout.
mve monitoring with varargout.
n=200;
v=3;
randn('state', 123456);
Y=randn(n,v);
% Contaminated data
Ycont=Y;
Ycont(1:5,:)=Ycont(1:5,:)+3;
[RAW,REW,C]=mveeda(Ycont,'msg',0,'plots',1);
Input Arguments
Output Arguments
More About
References
Rousseeuw, P.J. (1984), Least Median of Squares Regression, "Journal of the American Statistical Association", Vol. 79, pp. 871-881.
Rousseeuw, P.J. and Leroy A.M. (1987), Robust regression and outlier detection, Wiley New York.
Acknowledgements
This function follows the lines of MATLAB/R code developed during the years by many authors.
For more details see the R library robustbase http://robustbase.r-forge.r-project.org/ The core of these routines, e.g. the resampling approach, however, has been completely redesigned, with considerable increase of the computational performance.