supsmu
supsmu smooths scatterplots using Friedman's supersmoother algorithm.
Description
This function implements the supersmoother. This is basically the function supsmu written in MALTAB by Douglas M. Schwarz.
Email: dmschwarz=ieee*org, dmschwarz=urgrad*rochester*edu Real_email = regexprep(Email,{'=','*'},{'@','.'}) See the section "More About" of this file for the details of the modifications that have been made.
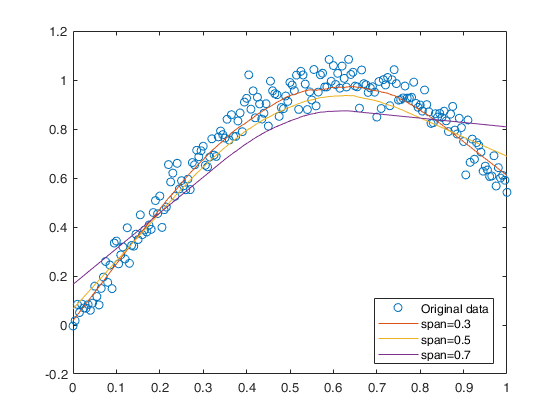
An example of the use of the option Span.smo
=supsmu(x,
y,
Name, Value)
Examples
 An example of the use of the option Span.
An example of the use of the option Span.
An example of the use of the option Span.
x = linspace(0,1,201);
y = sin(2.5*x) + 0.05*randn(1,201);
smo = supsmu(x,y,'Span',0.3);
smo1 = supsmu(x,y,'Span',0.5);
smo2 = supsmu(x,y,'Span',0.7);
plot(x,y,'o',x,[smo; smo1; smo2])
legend({'Original data' 'span=0.3' 'span=0.5' 'span=0.7'},'Location','best')
Input Arguments
Output Arguments
More About
References
Friedman, J. H. (1984). A Variable Span Smoother. Tech. Rep. No. 5, Laboratory for Computational Statistics, Dept. of Statistics, Stanford Univ., California.