tBothSides
tBothSides allows users to transform both sides of a (nonlinear) regression model.
Description
Examples
 Call of tBothSides with all default options.
Call of tBothSides with all default options.
Call of tBothSides with all default options.Load Assay data from Davidian M. and Haaland P. (1989).
% The Relationship Between Transformation and Weighting
% in Regression, With Application to Biological and Physical Science,
% Institute of Statistics mimeo series Report 1947, North Carolina State University.
% File is downloadable from
% https://pdfs.semanticscholar.org/7067/fd66fe06f114cac58eef8253eb7483edfd29.pdf
% The material assayed was obtained from two sources, with every other
% concentration starting with 0.476 from the first source and the remainder from the
% second. Replicate observations were obtained by subsampling at each concentration.
x=[0.476 0.924 1.905 3.696 7.619 14.874 30.474 59.134];
yy=[0.05706 0.11781 0.25071 0.49596 1.03928 2.14635 4.24397 8.53848...
0.057 0.11615 0.25398 0.4807 1.03659 2.09495 8.41333...
0.06363 0.12587 0.24552 0.49442 1.12641 2.24941 4.7011 9.01437...
0.05566 0.12308 0.24889 0.52321 1.10456 2.19937 4.44709 8.73544...
0.05449 0.11629 0.24858 0.49931 1.03184 2.16042 4.42707 8.33862...
0.06153 0.11878 0.24657 0.5021 1.02598 2.09198 4.39725 8.33347...
0.05837 0.11869 0.24212 0.4886 0.98267 2.07686 4.35511 8.35725...
0.05388 0.11886 0.25975 0.48158 1.04321 2.06961 4.37357 8.39123...
0.05618 0.12492 0.25311 0.4827 1.03838 2.12548 4.3204 8.3901];
X=[x';x([1:6 8])'; repmat(x(:),7,1)];
y=yy';
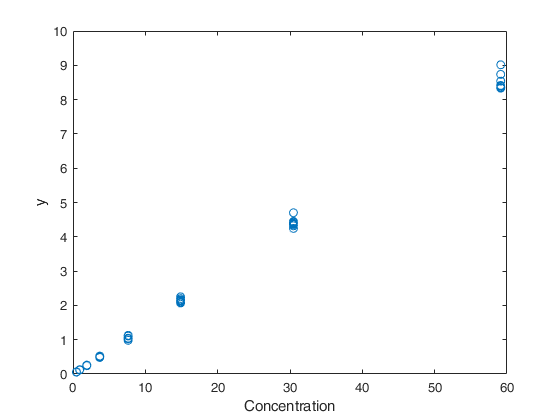
% The plot of the data shows: a systematic increase in variance with level
% of mean response, small variability relative to the range of the means,
% and reasonably straight-line relationship.
plot(X,y,'o')
xlabel('Concentration')
ylabel('y')
% In this case both, lambda and the beta coefficients are estimated
% A linear link between X and beta is assumed.
out=tBothSides(y, X);
disp(out.Btable)
bhat se tstat
_________ __________ _______
b1 -0.010677 0.0010009 -10.667
b2 0.14143 0.00085986 164.47
lambda 0.063929 0.081648 0.78298
Related Examples
Input Arguments
Output Arguments
More About
References
Box, G.E.P. and Cox, D.R. (1964), An analysis of transformations (with Discussion), "Journal of the Royal Statistical Society Series B", Vol. 26, pp. 211-252.
Carroll, R.J. and Ruppert, D. (1988), Transformation and Weighting in Regression, London: Chapman and Hall.
Yeo, I.K and Johnson, R. (2000), A new family of power transformations to improve normality or symmetry, "Biometrika", Vol. 87, pp. 954-959.