A vector with n elements that contains the response variable.
Missing values (NaN's) and infinite values (Inf's) are
allowed, since observations (rows) with missing or infinite
values will automatically be excluded from the
computations.
Data Types: single| double
Data matrix of explanatory variables (also called
'regressors') of dimension (n x p-1).
Rows of X represent observations, and columns represent
variables. Missing values (NaN's) and infinite values
(Inf's) are allowed, since observations (rows) with missing
or infinite values will automatically be excluded from the
computations.
PRIOR INFORMATION
$\beta$ is assumed to have a normal distribution with
mean $\beta_0$ and (conditional on $\tau_0$) covariance
$(1/\tau_0) (X_0'X_0)^{-1}$.
$\beta \sim N( \beta_0, (1/\tau_0) (X_0'X_0)^{-1} )$
Data Types: single| double
Data Types: single| double
It can be interpreted as $X_0'X_0$ where $X_0$ is a n0 x p
matrix coming from previous experiments (assuming that the
intercept is included in the model)
The prior distribution of $\tau_0$ is a gamma distribution with
parameters $a_0$ and $b_0$, that is
\[ p(\tau_0) \propto \tau^{a_0-1} \exp (-b_0 \tau)
\qquad E(\tau_0)= a_0/b_0 \]
Data Types: single| double
Prior estimate of $\tau=1/ \sigma^2 =a_0/b_0$.
Data Types: single| double
Sometimes it helps
to think of the prior information as coming from n0
previous experiments. Therefore we assume that matrix X0
(which defines R), was made up of n0 observations.
Data Types: single| double
Specify optional comma-separated pairs of Name,Value arguments.
Name is the argument name and Value
is the corresponding value. Name must appear
inside single quotes (' ').
You can specify several name and value pair arguments in any order as
Name1,Value1,...,NameN,ValueN.
Example:
'bsb',[3,6,9]
, 'init',100 starts monitoring from step m=100
, 'intercept',false
, 'plots',1
, 'bsbsteps',[10,20,30]
, 'nocheck',true
, 'msg',1
m x 1 vector containing the units forming initial subset. The
default value of bsb is '' (empty value), that is we
initialize the search just using prior information.
Example: 'bsb',[3,6,9]
Data Types: double
It specifies the point where to start monitoring
required diagnostics. If it is not specified it is set
equal to:
p+1, if the sample size is smaller than 40;
min(3*p+1,floor(0.5*(n+p+1))), otherwise.
The minimum value of init is 0. In this case in the first
step we start monitoring at step m=0 (step just based on
prior information)
Example: 'init',100 starts monitoring from step m=100
Data Types: double
Indicator for the constant term (intercept) in the fit,
specified as the comma-separated pair consisting of
'Intercept' and either true to include or false to remove
the constant term from the model.
Example: 'intercept',false
Data Types: boolean
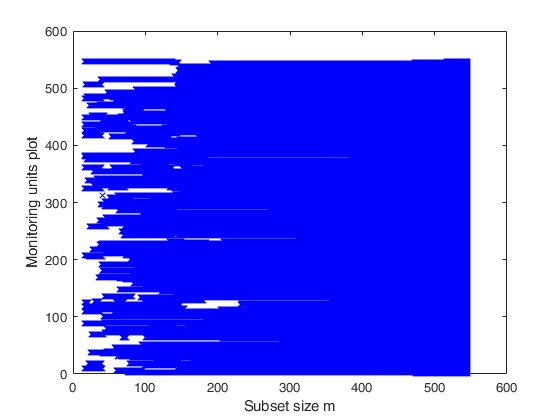
If plots=1 the monitoring units plot is displayed on the
screen. The default value of plots is 0 (that is no plot
is produced on the screen).
Example: 'plots',1
Data Types: double
If bsbsteps is 0 we store the units forming
subset in all steps. The default is store the units forming
subset in all steps if n<5000, else to store the units
forming subset at steps init and steps which are multiple
of 100. For example, if n=753 and init=6, units forming
subset are stored for m=init, 100, 200, 300, 400, 500 and
600.
Example: 'bsbsteps',[10,20,30]
Data Types: double
If nocheck is equal to true no check is performed on
matrix y and matrix X. Notice that y and X are left
unchanged. In other words the additional column of ones for
the intercept is not added. As default nocheck=false.
Example: 'nocheck',true
Data Types: boolean
It controls whether to display or not messages
about great interchange on the screen
If msg==1 (default) messages are displayed on the screen
else no message is displayed on the screen
Example: 'msg',1
Data Types: double
 FSRBbsb with optional arguments.
FSRBbsb with optional arguments.