corrNominal
corrNominal measures strength of association between two unordered (nominal) categorical variables.
Description
corrNominal computes $\chi2$, $\Phi$, Cramer's $V$, Goodman-Kruskal's $\lambda_{y|x}$, Goodman-Kruskal's $\tau_{y|x}$, and Theil's $H_{y|x}$ (uncertainty coefficient).
All these indexes measure the association among two unordered qualitative variables.
If the input table is 2-by-2 indexes theta (cross product ratio), Q=(theta-1)/(theta+1) and U=Q=(sqrt(theta)-1)/(sqrt(theta)+1) are also computed.
Additional details about these indexes can be found in the "More About" section or in the "Output section" of this document.
Example of option conflev.out
=corrNominal(N,
Name, Value)
Examples
 corrNominal with all the default options.
corrNominal with all the default options.
corrNominal with all the default options.Rows of N indicate type of Bachelor degree: 'Economics' 'Law' 'Literature' Columns of N indicate employment type: 'Private_firm' 'Public_firm' 'Freelance' 'Unemployed'
N=[150 80 20 50 80 250 30 140 30 50 0 120]; out=corrNominal(N);
Chi2 index
221.2405
pvalue Chi2 index
5.6588e-45
Phi index
0.4704
Cramer's V
0.3326
Test of H_0: independence between rows and columns
Coeff se zscore pval
________ ________ ______ __________
CramerV 0.3326 0.024431 13.614 0
GKlambdayx 0.22581 0.028383 7.9556 1.7764e-15
tauyx 0.091674 0.013524 6.7788 1.2121e-11
Hyx 0.08716 0.011265 7.7374 1.0214e-14
-----------------------------------------
Indexes and 95% confidence limits
Value StandardError ConflimL ConflimU
________ _____________ ________ ________
CramerV 0.3326 0.024431 0.28471 0.37287
GKlambdayx 0.22581 0.028383 0.17018 0.28144
tauyx 0.091674 0.013524 0.065168 0.11818
Hyx 0.08716 0.011265 0.065082 0.10924
Example of option conflev.
Example of option conflev.Use data from Goodman Kruskal (1954).
N=[1768 807 189 47 946 1387 746 53 115 438 288 16]; out=corrNominal(N,'conflev',0.99);
Chi2 index
1.0735e+03
pvalue Chi2 index
1.1244e-228
Phi index
0.3973
Cramer's V
0.2810
Test of H_0: independence between rows and columns
Coeff se zscore pval
________ _________ ______ ____
CramerV 0.28095 0.0088396 31.784 0
GKlambdayx 0.19239 0.012158 15.825 0
tauyx 0.080883 0.0046282 17.476 0
Hyx 0.075341 0.0041619 18.102 0
-----------------------------------------
Indexes and 99% confidence limits
Value StandardError ConflimL ConflimU
________ _____________ ________ ________
CramerV 0.28095 0.0088396 0.25818 0.30241
GKlambdayx 0.19239 0.012158 0.16108 0.22371
tauyx 0.080883 0.0046282 0.068962 0.092805
Hyx 0.075341 0.0041619 0.064621 0.086061
Related Examples
Example: compare confidence interval for Cramer V.
Example: compare confidence interval for Cramer V.Use the 4 possible methods.
method={'ncchisq', 'ncchisqadj', 'fisher' 'fisheradj'};
% Use a contingency table referred to type of job vs wine delivery
rownam={'Butcher' 'Carpenter' 'Carter' 'Farmer' 'Hunter' 'Miller' 'Taylor'};
colnam={'Wine not delivered' 'Wine delivered'};
N=[85 9
214 56
212 19
100 17
139 15
109 16
172 29];
Ntable=array2table(N,'RowNames',rownam,'VariableNames',colnam);
ConfintV=zeros(4,2);
for i=1:4
out=corrNominal(Ntable,'conflimMethodCramerV',method{i});
ConfintV(i,:)=out.ConfLimtable{'CramerV',3:4};
end
disp(array2table(ConfintV,'RowNames',method,'VariableNames',{'Lower' 'Upper'}))Chi2 index
21.0290
pvalue Chi2 index
0.0018
Phi index
0.1328
Cramer's V
0.1328
Test of H_0: independence between rows and columns
Coeff se zscore pval
________ _________ ______ _________
CramerV 0.13282 0.04149 3.2013 0.0013679
GKlambdayx 0 0 NaN NaN
tauyx 0.017642 0.0078826 2.2381 0.025218
Hyx 0.021875 0.0095422 2.2924 0.021883
-----------------------------------------
Indexes and 95% confidence limits
Value StandardError ConflimL ConflimU
________ _____________ _________ ________
CramerV 0.13282 0.04149 0.051504 0.17582
GKlambdayx 0 0 0 0
tauyx 0.017642 0.0078826 0.0021921 0.033091
Hyx 0.021875 0.0095422 0.0031721 0.040577
Chi2 index
21.0290
pvalue Chi2 index
0.0018
Phi index
0.1328
Cramer's V
0.1328
Test of H_0: independence between rows and columns
Coeff se zscore pval
________ _________ ______ __________
CramerV 0.13282 0.023037 5.7657 8.1331e-09
GKlambdayx 0 0 NaN NaN
tauyx 0.017642 0.0078826 2.2381 0.025218
Hyx 0.021875 0.0095422 2.2924 0.021883
-----------------------------------------
Indexes and 95% confidence limits
Value StandardError ConflimL ConflimU
________ _____________ _________ ________
CramerV 0.13282 0.023037 0.087671 0.18959
GKlambdayx 0 0 0 0
tauyx 0.017642 0.0078826 0.0021921 0.033091
Hyx 0.021875 0.0095422 0.0031721 0.040577
Chi2 index
21.0290
pvalue Chi2 index
0.0018
Phi index
0.1328
Cramer's V
0.1328
Test of H_0: independence between rows and columns
Coeff se zscore pval
________ _________ ______ _________
CramerV 0.13282 0.028675 4.632 3.621e-06
GKlambdayx 0 0 NaN NaN
tauyx 0.017642 0.0078826 2.2381 0.025218
Hyx 0.021875 0.0095422 2.2924 0.021883
-----------------------------------------
Indexes and 95% confidence limits
Value StandardError ConflimL ConflimU
________ _____________ _________ ________
CramerV 0.13282 0.028675 0.076621 0.18818
GKlambdayx 0 0 0 0
tauyx 0.017642 0.0078826 0.0021921 0.033091
Hyx 0.021875 0.0095422 0.0031721 0.040577
Chi2 index
21.0290
pvalue Chi2 index
0.0018
Phi index
0.1328
Cramer's V
0.1328
Test of H_0: independence between rows and columns
Coeff se zscore pval
________ _________ ______ __________
CramerV 0.13282 0.028646 4.6366 3.5418e-06
GKlambdayx 0 0 NaN NaN
tauyx 0.017642 0.0078826 2.2381 0.025218
Hyx 0.021875 0.0095422 2.2924 0.021883
-----------------------------------------
Indexes and 95% confidence limits
Value StandardError ConflimL ConflimU
________ _____________ _________ ________
CramerV 0.13282 0.028646 0.076676 0.18824
GKlambdayx 0 0 0 0
tauyx 0.017642 0.0078826 0.0021921 0.033091
Hyx 0.021875 0.0095422 0.0031721 0.040577
Lower Upper
________ _______
ncchisq 0.051504 0.17582
ncchisqadj 0.087671 0.18959
fisher 0.076621 0.18818
fisheradj 0.076676 0.18824
CorrNominal when input is 2 by 2.
CorrNominal when input is 2 by 2.Indexes theta=cross product ratio, Q and U are also computed.
% X=advertisement memory (rows)
% Y=product purchase (columns)
N= [87 188;
42 406];
nam=["Yes" "No"];
Ntable=array2table(N,"RowNames",nam,"VariableNames",nam);
disp('Input 2x2 contingency table')
table(Ntable,RowNames=["X=advertisement memory" "advertisement memory "],VariableNames="Y=Product purchase")
out=corrNominal(Ntable)Input 2x2 contingency table
ans =
2×1 table
Y=Product purchase
__________________
Yes No
___ ___
X=advertisement memory Yes 87 188
advertisement memory No 42 406
Chi2 index
57.6071
pvalue Chi2 index
3.2006e-14
Phi index
0.2823
Cramer's V
0.2823
-------------------------------
2x2 contingency table indexes
th=cross product ratio
4.4734
Cross product ratio in the interval [-1 1]. Index Q=(th-1)/(th+1)
0.6346
Cross product ratio in the interval [-1 1]. Index U=(sqrt(th)-1)/(sqrt(th)+1)
0.3580
-------------------------------
Test of H_0: independence between rows and columns
Coeff se zscore pval
________ ________ ______ __________
CramerV 0.28227 0.037189 7.5902 3.1974e-14
GKlambdayx 0 0 NaN NaN
tauyx 0.079678 0.020787 3.8331 0.00012653
Hyx 0.082782 0.021327 3.8816 0.00010376
-----------------------------------------
Indexes and 95% confidence limits
Value StandardError ConflimL ConflimU
________ _____________ ________ ________
CramerV 0.28227 0.037189 0.20938 0.35516
GKlambdayx 0 0 0 0
tauyx 0.079678 0.020787 0.038937 0.12042
Hyx 0.082782 0.021327 0.040983 0.12458
out =
struct with fields:
N: [2×2 double]
Ntable: [2×2 table]
Chi2: 57.6071
Chi2pval: 3.2006e-14
Phi: 0.2823
CramerV: [0.2823 0.0372 7.5902 3.1974e-14]
GKlambdayx: [0 0 NaN NaN]
tauyx: [0.0797 0.0208 3.8331 1.2653e-04]
Hyx: [0.0828 0.0213 3.8816 1.0376e-04]
ConfLim: [4×4 double]
ConfLimtable: [4×4 table]
TestInd: [4×4 double]
TestIndtable: [4×4 table]
theta: 4.4734
Q: 0.6346
U: 0.3580
Contrib2Chi2: [2×2 double]
Contrib2Chi2table: [2×2 table]
Contrib2Hyx: [2×2 double]
Contrib2Hyxtable: [2×2 table]
Contrib2tauyx: [2×2 double]
Contrib2tauyxtable: [2×2 table]
Example of call to CorrNominal with optional input argument plots.
Example of call to CorrNominal with optional input argument plots.Load the Housetasks data (a contingency table containing the frequency of execution of 13 house tasks in the couple).
N=[156 14 2 4;
124 20 5 4;
77 11 7 13;
82 36 15 7;
53 11 1 57;
32 24 4 53;
33 23 9 55;
12 46 23 15;
10 51 75 3;
13 13 21 66;
8 1 53 77;
0 3 160 2;
0 1 6 153];
rowslab={'Laundry' 'Main-meal' 'Dinner' 'Breakfast' 'Tidying' 'Dishes' ...
'Shopping' 'Official' 'Driving' 'Finances' 'Insurance'...
'Repairs' 'Holidays'};
colslab={'Wife' 'Alternating' 'Husband' 'Jointly'};
Ntable=array2table(N,'VariableNames',colslab,'RowNames',rowslab);
% Call to corrNominal with option 'plots',true
corrNominal(Ntable,'plots',true);Chi2 index
1.9445e+03
pvalue Chi2 index
0
Phi index
1.0559
Cramer's V
0.6096
Test of H_0: independence between rows and columns
Coeff se zscore pval
_______ ________ ______ ____
CramerV 0.60963 0.016701 36.502 0
GKlambdayx 0.50787 0.018427 27.561 0
tauyx 0.40671 0.013787 29.5 0
Hyx 0.40833 0.013767 29.659 0
-----------------------------------------
Indexes and 95% confidence limits
Value StandardError ConflimL ConflimU
_______ _____________ ________ ________
CramerV 0.60963 0.016701 0.57689 0.63133
GKlambdayx 0.50787 0.018427 0.47175 0.54398
tauyx 0.40671 0.013787 0.37969 0.43374
Hyx 0.40833 0.013767 0.38134 0.43531
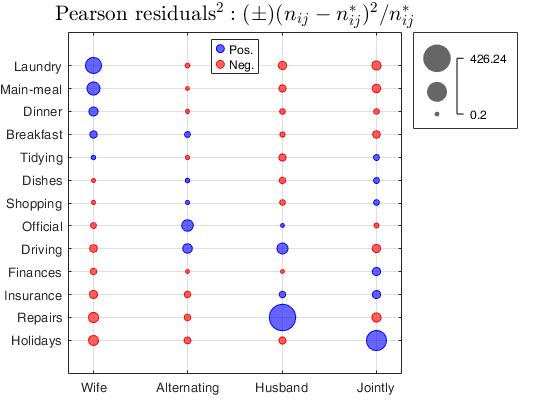
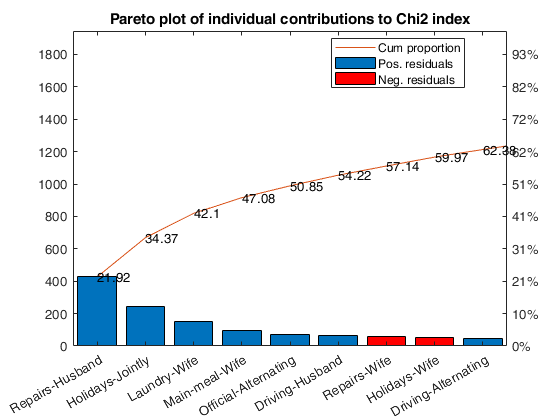
Input Arguments
Output Arguments
More About
References
Agresti, A. (2002), "Categorical Data Analysis", John Wiley & Sons. [pp.
23-26]
Goodman, L.A. and Kruskal, W.H. (1959), Measures of association for cross classifications II: Further Discussion and References, "Journal of the American Statistical Association", Vol. 54, pp. 123-163.
Goodman, L.A. and Kruskal, W.H. (1963), Measures of association for cross classifications III: Approximate Sampling Theory, "Journal of the American Statistical Association", Vol. 58, pp. 310-364.
Goodman, L.A. and Kruskal, W.H. (1972), Measures of association for cross classifications IV: Simplification of Asymptotic Variances, "Journal of the American Statistical Association", Vol. 67, pp. 415-421.
Liebetrau, A.M. (1983), "Measures of Association", Sage University Papers Series on Quantitative Applications in the Social Sciences, 07-004, Newbury Park, CA: Sage. [pp. 49-56]
Smithson, M.J. (2003), "Confidence Intervals", Quantitative Applications in the Social Sciences Series, No. 140. Thousand Oaks, CA: Sage. [pp.
39-41]
Acknowledgements
See Also
crosstab
|
rcontFS
|
CressieRead
|
corr
|
corrOrdinal