tclusteda
tclusteda computes tclust for a series of values of the trimming factor
Syntax
Description
tclusteda performs tclust for a series of values of the trimming factor alpha given k (number of groups) and given c (restriction factor). In order to increase the speed of the computations, parfor is used.
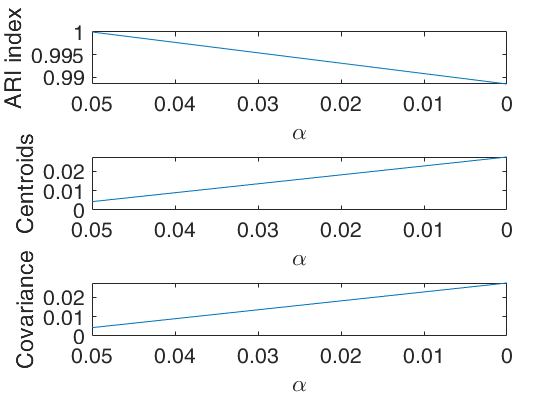
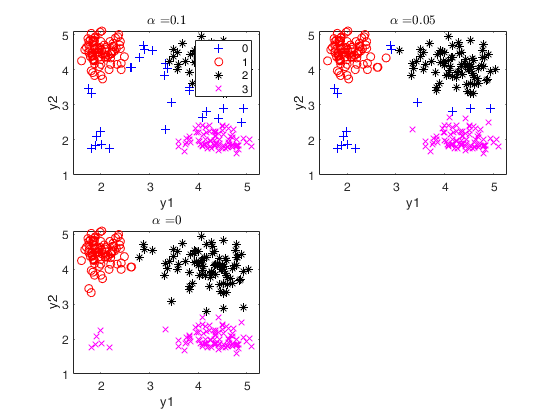
Monitoring using geyser data (all default options).out
=tclusteda(Y,
k,
alpha,
restrfactor)
Monitoring using geyser data with alpha and c specified.out
=tclusteda(Y,
k,
alpha,
restrfactor,
Name, Value)
Examples
 Monitoring using geyser data (all default options).
Monitoring using geyser data (all default options).
Monitoring using geyser data (all default options).
close all
delete(gcp("nocreate"));
parpool('Processes')
Y=load('geyser2.txt');
% alpha and restriction factor are not specified therefore for alpha
% vector [0.10 0.05 0] is used while for the restriction factor, value c=12
% is used
k=3;
[out]=tclusteda(Y,k);Parallel pool using the 'Processes' profile is shutting down.
Starting parallel pool (parpool) using the 'Processes' profile ...
Connected to parallel pool with 8 workers.
ans =
ProcessPool with properties:
Connected: true
NumWorkers: 8
Busy: false
Cluster: Processes (Local Cluster)
AttachedFiles: {}
AutoAddClientPath: true
FileStore: [1x1 parallel.FileStore]
ValueStore: [1x1 parallel.ValueStore]
IdleTimeout: 30 minutes (30 minutes remaining)
SpmdEnabled: true
Warning: You have not specified alpha: it is set to [0.10 0.05 0] by default
Warning: You have not specified restrfactor: it is set to 12 by default
Related Examples
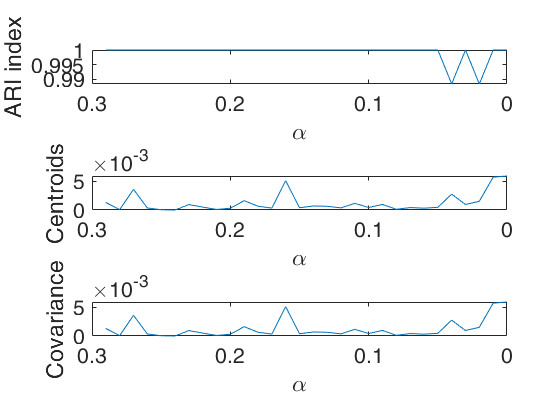
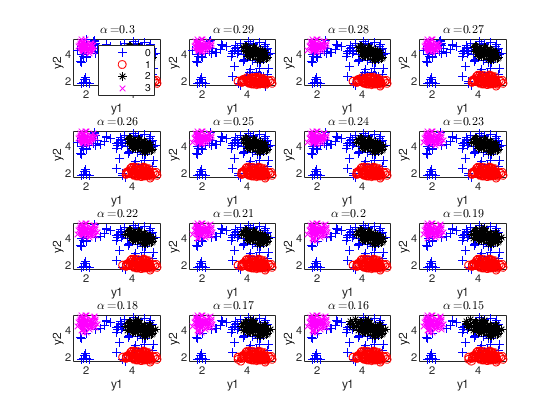
Monitoring geyser data with option UnitsSameGroup.
Monitoring geyser data with option UnitsSameGroup.
Y=load('geyser2.txt');
close all
delete(gcp("nocreate"));
parpool('Processes')
% alphavec= vector which contains the trimming levels to consider
alphavec=0.30:-0.10:0;
% c = restriction factor to use
c=100;
% k= number of groups
k=3;
% Make sure that group containing unit 10 is in a group which is labelled
% group 1 and group containing unit 12 is in group which is labelled group 2
UnitsSameGroup=[10 12];
% Mixture model is used
mixt=2;
[out]=tclusteda(Y,k,alphavec,1000,'mixt',2,'UnitsSameGroup',UnitsSameGroup);Parallel pool using the 'Processes' profile is shutting down.
Starting parallel pool (parpool) using the 'Processes' profile ...
Connected to parallel pool with 8 workers.
ans =
ProcessPool with properties:
Connected: true
NumWorkers: 8
Busy: false
Cluster: Processes (Local Cluster)
AttachedFiles: {}
AutoAddClientPath: true
FileStore: [1x1 parallel.FileStore]
ValueStore: [1x1 parallel.ValueStore]
IdleTimeout: 30 minutes (30 minutes remaining)
SpmdEnabled: true
MixLik with untrimmed units selected using h largest likelihood contributions
100%[===================================================]
tclusteda using simulated data.
tclusteda using simulated data.
delete(gcp("nocreate"));
parpool('Processes')
% 5 groups and 5 variables
rng(100,'twister')
n1=100;
n2=80;
n3=50;
n4=80;
n5=70;
v=5;
Y1=randn(n1,v)+5;
Y2=randn(n2,v)+3;
Y3=rand(n3,v)-2;
Y4=rand(n4,v)+2;
Y5=rand(n5,v);
group=ones(n1+n2+n3+n4+n5,1);
group(n1+1:n1+n2)=2;
group(n1+n2+1:n1+n2+n3)=3;
group(n1+n2+n3+1:n1+n2+n3+n4)=4;
group(n1+n2+n3+n4+1:n1+n2+n3+n4+n5)=5;
close all
Y=[Y1;Y2;Y3;Y4;Y5];
n=size(Y,1);
% Set number of groups
k=5;
% Example of the subsets precalculated
nsamp=2000;
nsampscalar=nsamp;
nsamp=subsets(nsamp,n,(v+1)*k);
% Random numbers to compute proportions computed once and for all
RandNumbForNini=rand(k,nsampscalar);
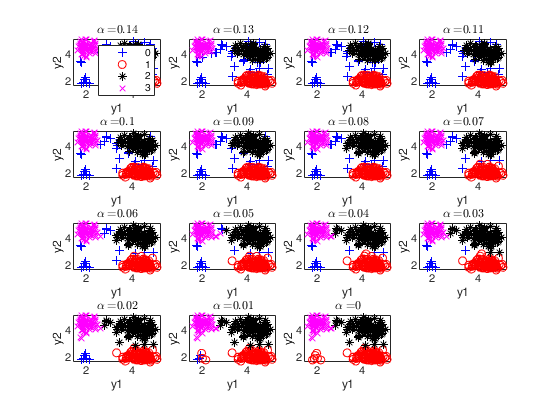
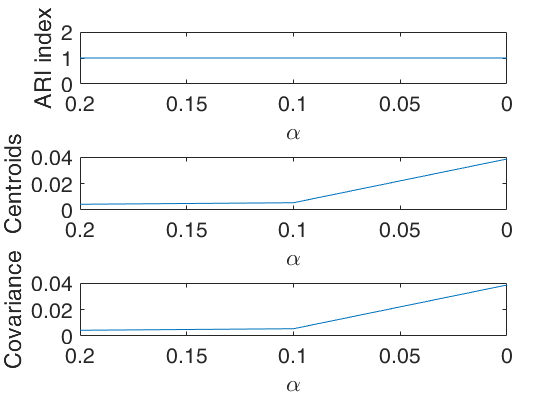
% The allocation is shown on the space of the first two principal
% components
out=tclusteda(Y,k,[],6,'plots',1,'RandNumbForNini',RandNumbForNini,'nsamp',nsamp);Parallel pool using the 'Processes' profile is shutting down.
Starting parallel pool (parpool) using the 'Processes' profile ...
Connected to parallel pool with 8 workers.
ans =
ProcessPool with properties:
Connected: true
NumWorkers: 8
Busy: false
Cluster: Processes (Local Cluster)
AttachedFiles: {}
AutoAddClientPath: true
FileStore: [1x1 parallel.FileStore]
ValueStore: [1x1 parallel.ValueStore]
IdleTimeout: 30 minutes (30 minutes remaining)
SpmdEnabled: true
Warning: You have not specified alpha: it is set to [0.10 0.05 0] by default
ClaLik with untrimmed units selected using crisp criterion
100%[===================================================]
Input Arguments
Output Arguments
More About
References
Garcia-Escudero, L.A., Gordaliza, A., Matran, C. and Mayo-Iscar, A. (2008), A General Trimming Approach to Robust Cluster Analysis. Annals of Statistics, Vol. 36, 1324-1345.