
|
FSMfan |
FSMmmd |
 |
FSMinvmmd
FSMinvmmd converts values of minimum Mahalanobis distance into confidence levels
Description
Examples
Related Examples
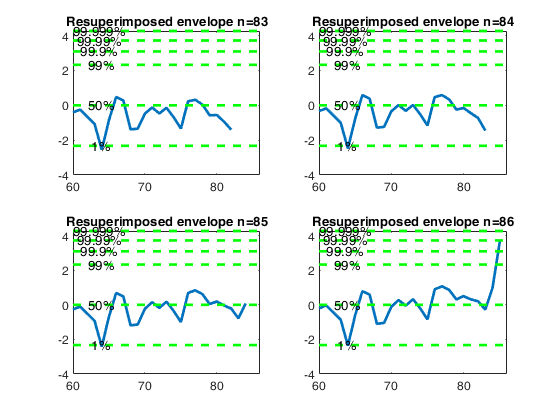
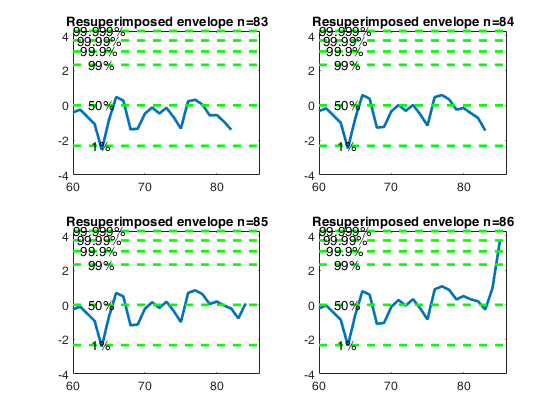
 Resuperimposing envelopes and normal coordinates.
Resuperimposing envelopes and normal coordinates.
Resuperimposing envelopes and normal coordinates.Comparison of resuperimposing envelopes using mmd coordinates and normal coordinates. Forgery Swiss Banknotes data.
load('swiss_banknotes');
Y=swiss_banknotes{:,:};
Y=Y(101:200,:);
% The line below shows the plot of mmd
[out]=FSM(Y,'plots',2);
n0=83:86;
quantplo=[0.01 0.5 0.99 0.999 0.9999 0.99999];
ninv=norminv(quantplo);
lwdenv=2;
supn0=max(n0);
ij=0;
for jn0=n0;
ij=ij+1;
MMDinv = FSMinvmmd(out.mmd,size(Y,2),'n',jn0);
% Resuperimposed envelope in normal coordinates
subplot(2,2,ij)
plot(MMDinv(:,1),MMDinv(:,3),'LineWidth',2)
xlim([out.mmd(1,1) supn0])
v=axis;
line(v(1:2)',[ninv;ninv],'color','g','LineWidth',lwdenv,'LineStyle','--','Tag','env');
text(v(1)*ones(length(quantplo),1),ninv',strcat(num2str(100*quantplo'),'%'));
title(['Resuperimposed envelope n=' num2str(jn0)]);
end
-------------------------
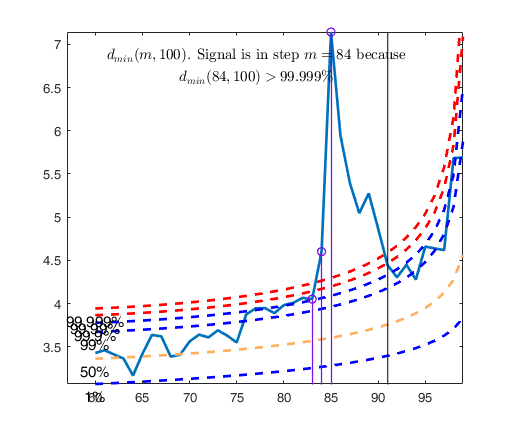
Signal detection loop
Tentative signal in central part of the search: step m=84 because
dmin(84,100)>99.999%
-------------------
Signal validation
Validated signal
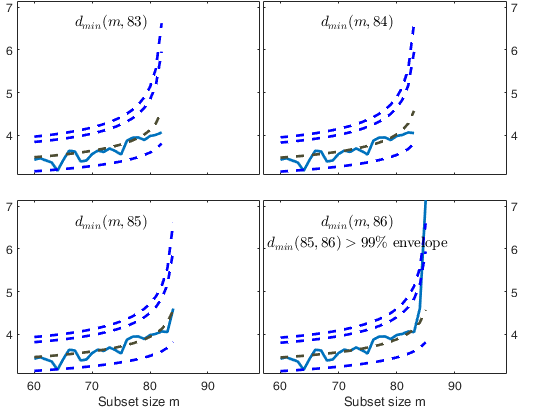
-------------------------------
Start resuperimposing envelopes from step m=83
Superimposition stopped because d_{min}(85,86)>99% envelope
$d_{min}(85,86)>99$\% envelope
----------------------------
Final output
Number of units declared as outliers=15
Summary of the exceedances
1 99 999 9999 99999
0 21 15 7 7
Input Arguments
Output Arguments
More About
References
Atkinson, A.C. and Riani, M. (2006), Distribution theory and simulations for tests of outliers in regression, "Journal of Computational and Graphical Statistics", Vol. 15, pp. 460-476.
Riani, M. and Atkinson, A.C. (2007), Fast calibrations of the forward search for testing multiple outliers in regression, "Advances in Data Analysis and Classification", Vol. 1, pp. 123-141.
|
|
FSMfan |
FSMmmd |
|
|
|
Functions |
|
• The developers of the toolbox • The forward search group • Terms of Use • Acknowledgments