tclustICsol
tclustICsol extracts a set of best relevant solutions
Description
tclustICsol takes as input the output of function tclustIC or tclustICreg (that is a series of matrices which contain the values of the information criteria BIC/ICL/CLA for different values of and c (or \alpha) and extracts the first best solutions. Two solutions are considered equivalent if the value of the adjusted Rand index (or the adjusted Fowlkes and Mallows index) is above a certain threshold.
For each tentative solution the program checks the adjacent values of c (\alpha) for which the solution is stable. A matrix with adjusted Rand indexes is given for the extracted solutions.
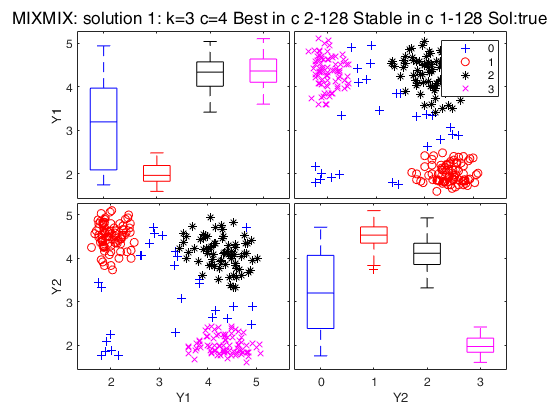
Simulated data: compare first 3 best solutions using MIXMIX and CLACLA.out
=tclustICsol(IC,
Name, Value)
Examples
 Plot of first two best solutions for Geyser data.
Plot of first two best solutions for Geyser data.
Plot of first two best solutions for Geyser data.
Y=load('geyser2.txt');
outIC=tclustIC(Y,'cleanpool',false,'plots',0,'alpha',0.1);
% Plot first two best solutions using as Information criterion MIXMIX
disp('Best solutions using MIXMIX')
[out]=tclustICsol(outIC,'whichIC','MIXMIX','plots',1,'NumberOfBestSolutions',2);
disp(out.MIXMIXbs)
k=1
k=2
k=3
k=4
k=5
Best solutions using MIXMIX
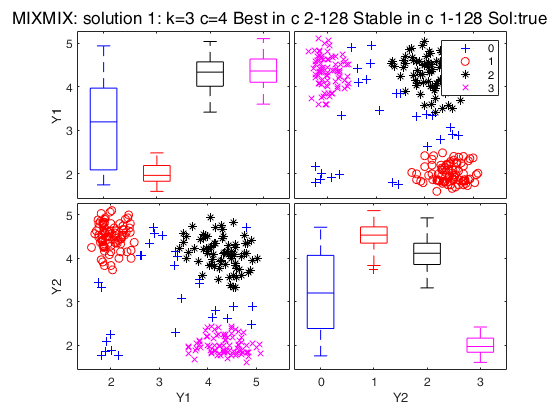
{[3]} {[ 4]} {7×1 double} {[ 1]} {'true' }
{[4]} {[32]} {8×1 double} {0×0 double} {'spurious'}
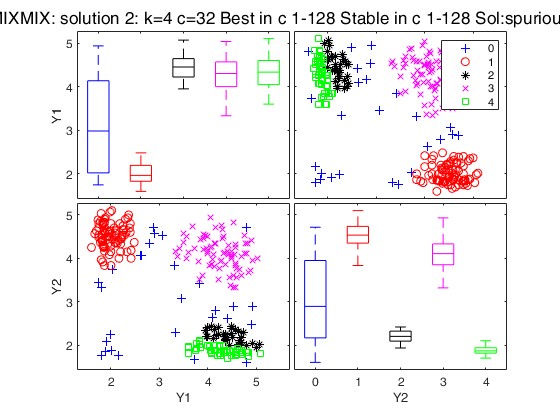

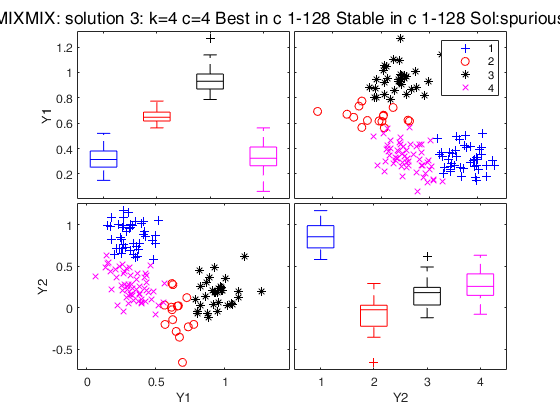
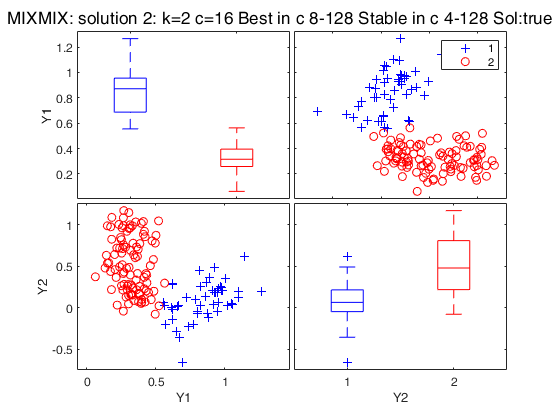
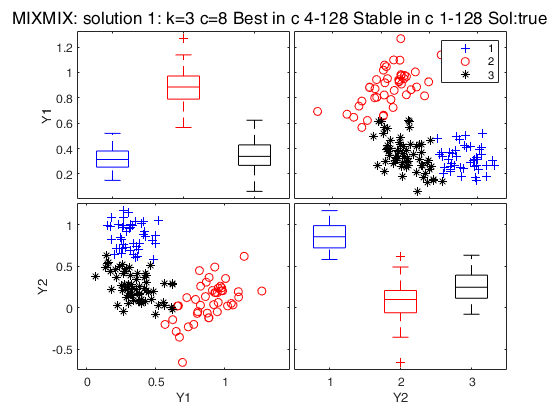
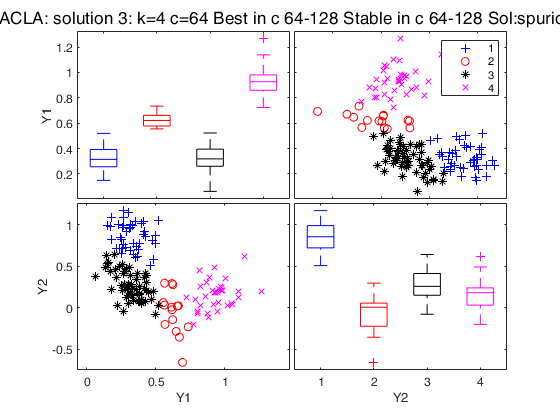
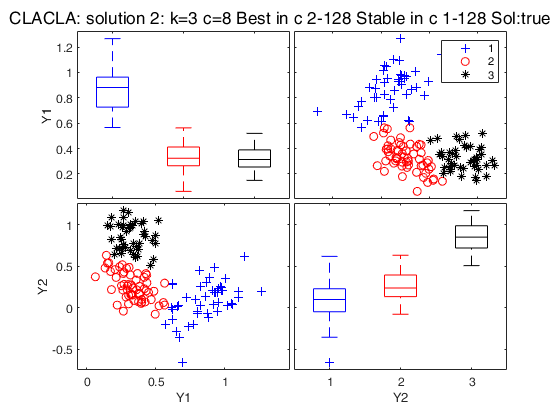
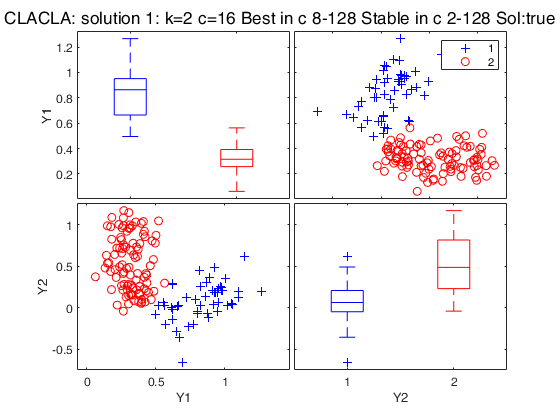
Simulated data: compare first 3 best solutions using MIXMIX and CLACLA.
Simulated data: compare first 3 best solutions using MIXMIX and CLACLA.Data generation
restrfact=5;
rng('default') % Reinitialize the random number generator to its startup configuration
rng(20000);
ktrue=3;
% n = number of observations
n=150;
% v= number of dimensions
v=2;
% Imposed average overlap
BarOmega=0.04;
outMS=MixSim(ktrue,v,'BarOmega',BarOmega, 'restrfactor',restrfact);
% data generation given centroids and cov matrices
[Y,id]=simdataset(n, outMS.Pi, outMS.Mu, outMS.S);
% Computation of information criterion
outIC=tclustIC(Y,'cleanpool',false,'plots',0,'nsamp',200);
% Plot first 3 best solutions using as Information criterion MIXMIX
disp('Best 3 solutions using MIXMIX')
[outMIXMIX]=tclustICsol(outIC,'whichIC','MIXMIX','plots',1,'NumberOfBestSolutions',3);
disp(outMIXMIX.MIXMIXbs)
disp('Best 3 solutions using CLACLA')
[outCLACLA]=tclustICsol(outIC,'whichIC','CLACLA','plots',1,'NumberOfBestSolutions',3);
disp(outCLACLA.CLACLAbs)
k=1
k=2
k=3
k=4
k=5
Best 3 solutions using MIXMIX
{[3]} {[ 8]} {6×1 double} {2×1 double} {'true' }
{[2]} {[16]} {5×1 double} {[ 4]} {'true' }
{[4]} {[ 4]} {8×1 double} {0×0 double} {'spurious'}
Best 3 solutions using CLACLA
{[2]} {[16]} {5×1 double} {2×1 double} {'true' }
{[3]} {[ 8]} {7×1 double} {[ 1]} {'true' }
{[4]} {[64]} {2×1 double} {0×1 double} {'spurious'}


Related Examples
Input Arguments
Output Arguments
References
Cerioli, A., Garcia-Escudero, L.A., Mayo-Iscar, A. and Riani M. (2017), Finding the Number of Groups in Model-Based Clustering via Constrained Likelihoods, "Journal of Computational and Graphical Statistics", pp. 404-416, https://doi.org/10.1080/10618600.2017.1390469
Hubert L. and Arabie P. (1985), Comparing Partitions, "Journal of Classification", Vol. 2, pp. 193-218.
See Also
tclustIC
|
tclust
|
tclustregIC
|
tclustreg
|
carbikeplot