FSRcp
FSRcp monitors Cp and AIC for all models of interest of size smallp
Description
Examples
 FSRcp with optional arguments.
FSRcp with optional arguments.
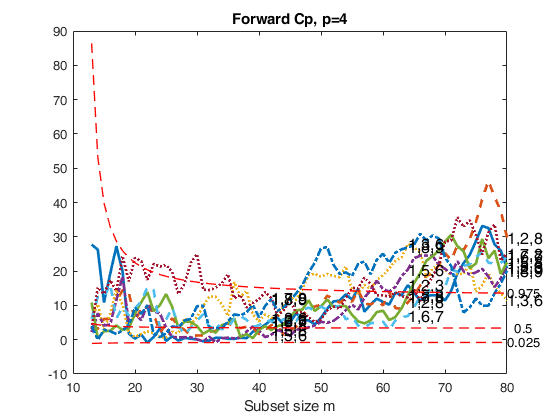
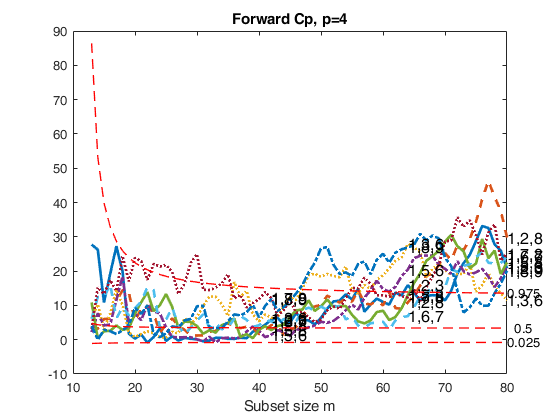
FSRcp with optional arguments.Extract the best models of size 4, and show the plot of forward Cp.
X=load('ozone.txt');
% Transform the response using logs
X(:,end)=log(X(:,end));
% Add a time trend
X=[(-40:39)' X];
% Define y
y=X(:,end);
% Define X
X=X(:,1:end-1);
smallp=4;
[outCp]=FSRcp(y,X,smallp,'plots',1);Warning: Rank deficient, rank = 3, tol = 1.420154e-11. Warning: Rank deficient, rank = 3, tol = 1.854420e-11. Warning: Rank deficient, rank = 3, tol = 2.342010e-11. Warning: Rank deficient, rank = 3, tol = 2.858564e-11. Warning: Rank deficient, rank = 3, tol = 3.410996e-11. Warning: Rank deficient, rank = 3, tol = 1.241267e-11. Warning: Rank deficient, rank = 3, tol = 1.631688e-11. Warning: Rank deficient, rank = 3, tol = 2.056162e-11. Warning: Rank deficient, rank = 3, tol = 2.512148e-11. Warning: Rank deficient, rank = 3, tol = 2.997602e-11. Warning: Rank deficient, rank = 3, tol = 1.631688e-11. Warning: Rank deficient, rank = 3, tol = 2.056162e-11. Warning: Rank deficient, rank = 3, tol = 2.512148e-11. Warning: Rank deficient, rank = 3, tol = 2.997602e-11. Warning: Rank deficient, rank = 3, tol = 2.056162e-11. Warning: Rank deficient, rank = 3, tol = 2.512148e-11. Warning: Rank deficient, rank = 3, tol = 2.997602e-11.
Related Examples
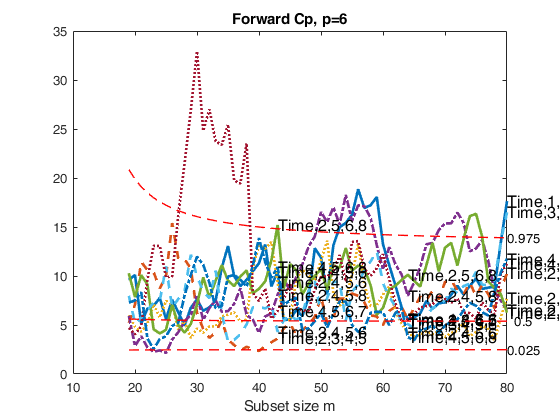
Extract the best models of size 6 and 5 and plot monitoring of Cp.
Extract the best models of size 6 and 5 and plot monitoring of Cp.Extract 1000 subsets to initialize the search and use labels defined by the user. Exclude the searches of the models which were unacceptable for smallp=5.
X=load('ozone.txt');
% Transform the response using logs
X(:,end)=log(X(:,end));
% Add a time trend
X=[(-40:39)' X];
% Define y
y=X(:,end);
% Define X
X=X(:,1:end-1);
smallp=6;
labels={'Time','1','2','3','4','5','6','7','8'};
[Cpmon6]=FSRcp(y,X,smallp,'nsamp',1000,'plots',1,'labels',labels);
smallp=5;
[Cpmon5]=FSRcp(y,X,smallp,'nsamp',1000,'Excl',Cpmon6.Ajout,'plots',1,'labels',labels);Warning: Rank deficient, rank = 4, tol = 1.631688e-11. Warning: Rank deficient, rank = 4, tol = 2.056162e-11. Warning: Rank deficient, rank = 4, tol = 2.512148e-11. Warning: Rank deficient, rank = 4, tol = 2.997602e-11.
Input Arguments
Output Arguments
References
Atkinson, A.C. and Riani, M. (2008), A robust and diagnostic information criterion for selecting regression models, "Journal of the Japan Statistical Society", Vol. 38, pp. 3-14.