FSRmdr
FSRmdr computes minimum deletion residual and other basic linear regression quantities in each step of the search
Syntax
Description
Examples
Related Examples
 Monitoring of s2, and the evolution of beta coefficients for the Hawkins dataset
load('hawkins.
Monitoring of s2, and the evolution of beta coefficients for the Hawkins dataset
load('hawkins.
Monitoring of s2, and the evolution of beta coefficients for the Hawkins dataset
load('hawkins.
load('hawkins.txt');
y=hawkins(:,9);
X=hawkins(:,1:8);
[out]=LXS(y,X,'nsamp',10000);
[~,~,~,Bols,S2] = FSRmdr(y,X,out.bs);
if isnan(S2)
disp('NoFullRank in initial subset, please rerun FSRmdr')
else
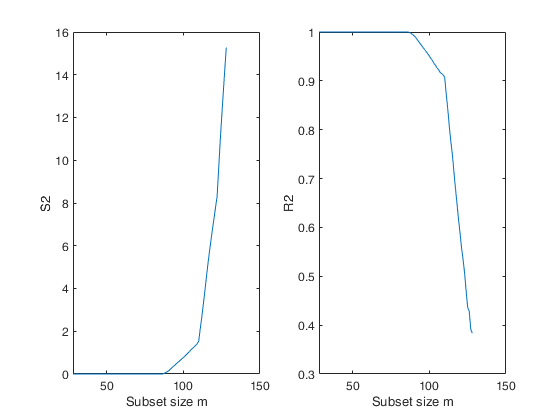
%The forward plot of s2 shows that initially the estimate is virtually
%zero. The four line segments comprising the plot correspond to the four
%groups of observations
% Plot of the monitoring of S2 and R2
figure;
subplot(1,2,1)
plot(S2(:,1),S2(:,2))
xlabel('Subset size m');
ylabel('S2');
subplot(1,2,2)
plot(S2(:,1),S2(:,3))
xlabel('Subset size m');
ylabel('R2');
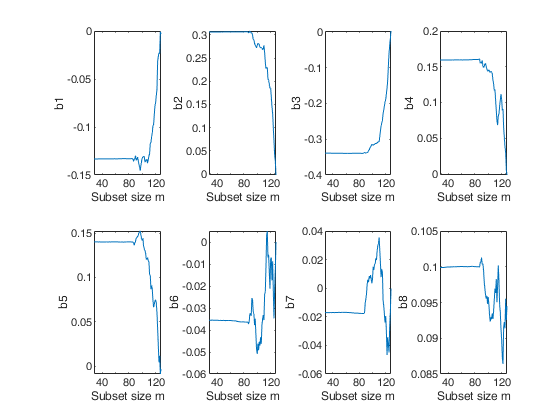
%The forward plots of the estimates of the beta coefficients show that they are virtually constant until m = 86, after which they start fluctuating in different directions.
% Plots of the monitoring of "Estimates of beta coefficients"
figure;
for j=3:size(Bols,2)
subplot(2,4,j-2)
plot(Bols(:,1),Bols(:,j))
xlabel('Subset size m');
ylabel(['b' num2str(j-2)]);
end
endTotal estimated time to complete LMS: 0.12 seconds
Store units forming subsets in selected steps.
Store units forming subsets in selected steps.In this example the units forming subset are stored just for selected steps.
load('hawkins.txt');
y=hawkins(:,9);
X=hawkins(:,1:8);
rng('default')
rng(100)
[out]=LXS(y,X,'nsamp',10000);
[mdr,Un,BB,Bols,S2] = FSRmdr(y,X,out.bs,'bsbsteps',[30 60]);
if isnan(S2)
disp('NoFullRank in initial subset, please rerun FSRmdr')
else
% BB has just two columns
% First column contains information about units forming subset at step m=30
% sum(~isnan(BB(:,1))) is 30
% Second column contains information about units forming subset at step m=60
% sum(~isnan(BB(:,2))) is 60
disp(sum(~isnan(BB(:,1))))
disp(sum(~isnan(BB(:,2))))
endTotal estimated time to complete LMS: 0.07 seconds
30
60
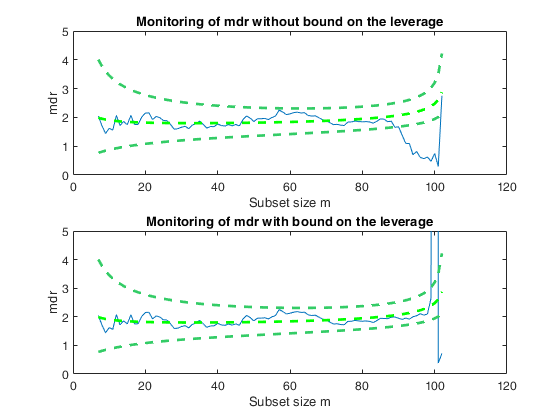
Example of the use of option threshlevoutX.
Example of the use of option threshlevoutX.In this example, a set of remote units is added to a cloud of points.
% The purpose of this example is to show that in presence of units very far
% from the bulk of the data (bad or good leverage points) it is necessary to
% bound their effect putting a constraint on their leverage hi=xi'(X'X)xi
rng(10000)
n=100;
p=1;
X=randn(n,p);
epsil=10;
beta=ones(p,1);
y=X*beta+randn(n,1)*epsil;
% Add 10 very remote points
add=3;
Xadd=X(1:add,:)+5000;
yadd=y(1:add)+200;
Xall=[X;Xadd];
yall=[y;yadd];
outLXS=LXS(y,X);
bs=outLXS.bs;
subplot(2,1,1)
out1=FSRmdr(yall,Xall,bs,'plots',1);
xylim=axis;
ylabel('mdr')
title('Monitoring of mdr without bound on the leverage')
subplot(2,1,2)
out2=FSRmdr(yall,Xall,bs,'plots',1,'threshlevoutX',10);
ylim(xylim(3:4));
ylabel('mdr')
title('Monitoring of mdr with bound on the leverage')Total estimated time to complete LMS: 0.02 seconds Warning: Upper limit of y axis of the mdr forward plot set to 20
Input Arguments
Output Arguments
More About
References
Atkinson, A.C. and Riani, M. (2000), "Robust Diagnostic Regression Analysis", Springer Verlag, New York.
Atkinson, A.C. and Riani, M. (2006), Distribution theory and simulations for tests of outliers in regression, "Journal of Computational and Graphical Statistics", Vol. 15, pp. 460-476.
Riani, M. and Atkinson, A.C. (2007), Fast calibrations of the forward search for testing multiple outliers in regression, "Advances in Data Analysis and Classification", Vol. 1, pp. 123-141.