ace
ace computes alternative conditional expectation
Description
This function uses the alternating conditional expectation algorithm to find the transformations of y and X that maximise the proportion of variation in y explained by X. When X is a matrix, it is transformed so that its columns are equally weighted when predicting y.
Example 1 from TIB88: brain body weight data.out
=ace(y,
X,
Name, Value)
Examples
 Example of the use of ace based on the Wang and Murphy data.
Example of the use of ace based on the Wang and Murphy data.
Example of the use of ace based on the Wang and Murphy data.In order to have the possibility of replicating the results in R using library acepack function mtR is used to generate the random data.
rng('default')
seed=11;
negstate=-30;
n=200;
X1 = mtR(n,0,seed)*2-1;
X2 = mtR(n,0,negstate)*2-1;
X3 = mtR(n,0,negstate)*2-1;
X4 = mtR(n,0,negstate)*2-1;
res=mtR(n,1,negstate);
% Generate y
y = log(4 + sin(3*X1) + abs(X2) + X3.^2 + X4 + .1*res );
X = [X1 X2 X3 X4];
% Apply the ace algorithm
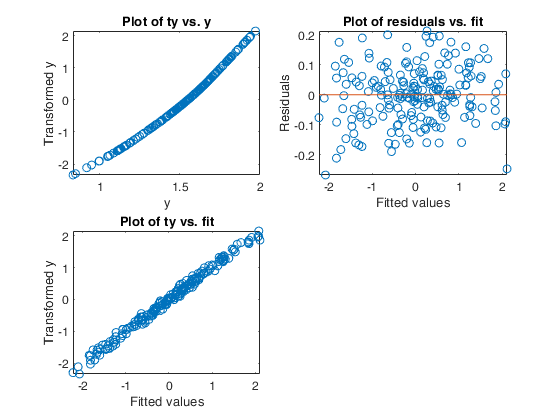
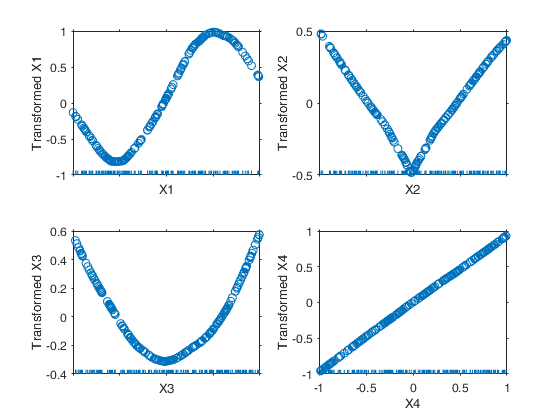
out= ace(y,X);
% Show the output graphically using function aceplot
aceplot(out)
Input Arguments
Output Arguments
References
Breiman, L. and Friedman, J.H. (1985), Estimating optimal transformations for multiple regression and correlation, "Journal of the American Statistical Association", Vol. 80, pp. 580-597.
Wang D. and Murphy M. (2005), Identifying nonlinear relationships regression using the ACE algorithm, "Journal of Applied Statistics", Vol. 32, pp. 243-258.