
|
mdpdR |
mdrplot |
 |
mdpdReda
mdpdReda allows to monitor Minimum Density Power Divergence criterion to parametric regression problems.
Description
Examples
Related Examples
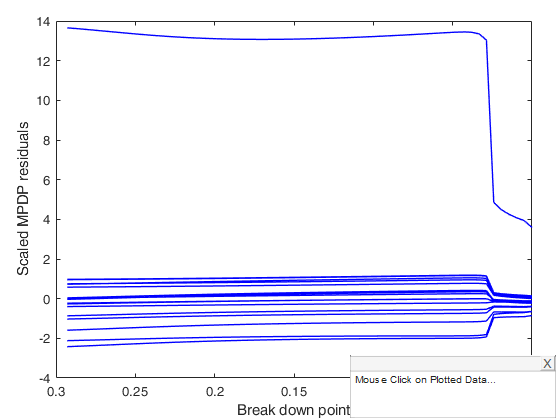
 mdpdReda applied to Forbes data.
mdpdReda applied to Forbes data.
mdpdReda applied to Forbes data.
load('forbes.txt');
y=forbes(:,2);
X=forbes(:,1);
[outalpha0] = mdpdReda(y, X, 'plots',1);
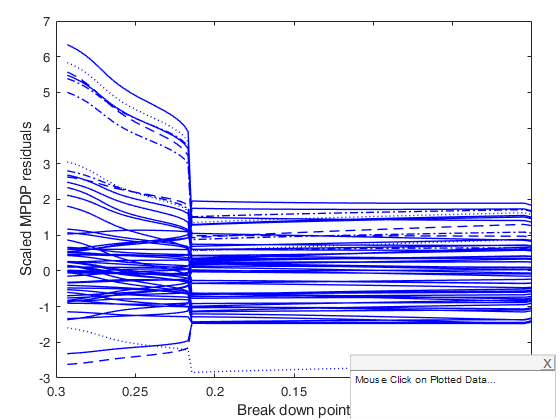
mdpdReda applied to multiple regression data.
mdpdReda applied to multiple regression data.
load('multiple_regression.txt');
y=multiple_regression(:,4);
X=multiple_regression(:,1:3);
[out] = mdpdReda(y, X, 'plots',1);
Input Arguments
Output Arguments
More About
References
Basu, A., Harris, I.R., Hjort, N.L. and Jones, M.C., (1998), Robust and efficient estimation by minimizing a density power divergence, "Biometrika", Vol. 85, pp. 549-559.
69-83.
Durio A., Isaia E.D. (2011), The Minimum Density Power Divergence Approach in Building Robust Regression Models, "Informatica", Vol. 22, pp. 43-56.
|
|
mdpdR |
mdrplot |
|
|
|
Functions |
|
• The developers of the toolbox • The forward search group • Terms of Use • Acknowledgments