LTSts
LTSts extends LTS estimator to time series
Description
It is possible to set a model with a trend (up to third order), a seasonality (constant or of varying amplitude and with a different number of harmonics) and a level shift (in this last case it is possible to specify the window in which level shift has to be searched for).
Airline data: linear trend + just one harmonic for seasonal component.out
=LTSts(y,
Name, Value)
Examples
Related Examples
 Example 1 used in the paper RPRH.
Example 1 used in the paper RPRH.
Example 1 used in the paper RPRH.Load airline data.
% 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960
y = [112 115 145 171 196 204 242 284 315 340 360 417 % Jan
118 126 150 180 196 188 233 277 301 318 342 391 % Feb
132 141 178 193 236 235 267 317 356 362 406 419 % Mar
129 135 163 181 235 227 269 313 348 348 396 461 % Apr
121 125 172 183 229 234 270 318 355 363 420 472 % May
135 149 178 218 243 264 315 374 422 435 472 535 % Jun
148 170 199 230 264 302 364 413 465 491 548 622 % Jul
148 170 199 242 272 293 347 405 467 505 559 606 % Aug
136 158 184 209 237 259 312 355 404 404 463 508 % Sep
119 133 162 191 211 229 274 306 347 359 407 461 % Oct
104 114 146 172 180 203 237 271 305 310 362 390 % Nov
118 140 166 194 201 229 278 306 336 337 405 432 ]; % Dec
% Two short level shifts in opposite directions and an isolated outlier.
% Add a level shift contamination plus some outliers.
y1=y(:);
y1(50:55)=y1(50:55)-300;
y1(70:75)=y1(70:75)+300;
y1(90:90)=y1(90:90)+300;
% Create structure specifying model
model=struct;
model.trend=2; % quadratic trend
model.s=12; % monthly time series
model.seasonal=204; % number of harmonics
model.lshift=41:length(y1)-40; % position where monitoring level shift
model.X=[];
% Create structure lts specifying lts options
lshiftlocref=struct;
% Set window length for local refinement.
lshiftlocref.wlength=10;
% Set tuning constant to use inside Huber rho function
lshiftlocref.huberc=1.5;
% Estimate the parameters
[out]=LTSts(y1,'model',model,'nsamp',500,...
'plots',1,'lshiftlocref',lshiftlocref,'msg',0);
% Using the notation of the paper RPRH: A=2, B=4, G=2 and $\delta_1>0$.
str=strcat('A=2, B=4, G=2, $\delta_2=',num2str(out.posLS),'$');
numpar = {'model parameters:' , str};
axeslast=findobj('-regexp','Tag','LTSts:ts');
title(axeslast(end),numpar,'interpreter','LaTeX','FontSize',16);
% generate the wedgeplot
% wedgeplot(out,'transpose',true,'extradata',[y1 out.yhat]);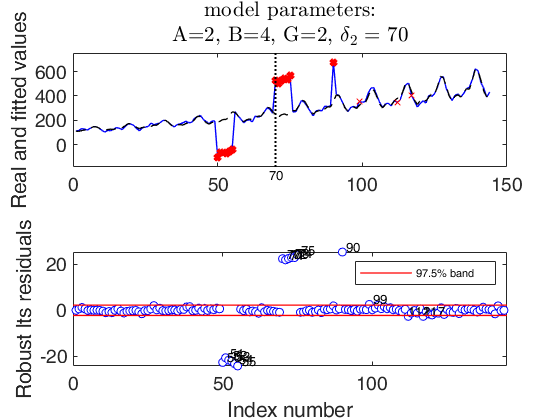
Example 2 used in the paper RPRH.
Example 2 used in the paper RPRH.A persisting level shift and three isolated outliers, two of which in proximity of the level shift.
% Load airline data.
% 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960
y = [112 115 145 171 196 204 242 284 315 340 360 417 % Jan
118 126 150 180 196 188 233 277 301 318 342 391 % Feb
132 141 178 193 236 235 267 317 356 362 406 419 % Mar
129 135 163 181 235 227 269 313 348 348 396 461 % Apr
121 125 172 183 229 234 270 318 355 363 420 472 % May
135 149 178 218 243 264 315 374 422 435 472 535 % Jun
148 170 199 230 264 302 364 413 465 491 548 622 % Jul
148 170 199 242 272 293 347 405 467 505 559 606 % Aug
136 158 184 209 237 259 312 355 404 404 463 508 % Sep
119 133 162 191 211 229 274 306 347 359 407 461 % Oct
104 114 146 172 180 203 237 271 305 310 362 390 % Nov
118 140 166 194 201 229 278 306 336 337 405 432 ]; % Dec
close all
y1=y(:);
y1(68:end)=y1(68:end)+1300;
y1(67)=y1(67)-600;
y1(45)=y1(45)-800;
y1(68:69)=y1(68:69)+800;
% Create structure specifying model
model=struct;
model.trend=2; % quadratic trend
model.s=12; % monthly time series
model.seasonal=204; % number of harmonics
model.lshift=41:length(y1)-40; % position where monitoring level shift
model.X=[];
% Create structure lts specifying lts options
lshiftlocref=struct;
% Set window length for local refinement.
lshiftlocref.wlength=10;
% Set tuning constant to use inside Huber rho function
lshiftlocref.huberc=1.5;
% Estimate the parameters
[out, varargout]=LTSts(y1,'model',model,'nsamp',500,...
'plots',1,'lshiftlocref',lshiftlocref,'msg',0);
% Using the notation of the paper RPRH: A=2, B=4, G=2 and $\delta_1>0$.
str=strcat('A=2, B=4, G=2, $\delta_2=',num2str(out.posLS),'$');
numpar = {'model parameters:' , str};
title(findobj('-regexp','Tag','LTSts:ts'),numpar,'interpreter','LaTeX','FontSize',16);
% generate the wedgeplot
% wedgeplot(out,'transpose',true,'extradata',[y1 out.yhat]);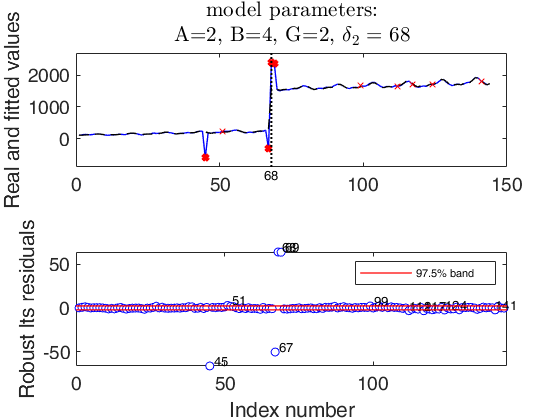
Example 3 used in the paper RPRH.
Example 3 used in the paper RPRH.A persisting level shift preceded and followed in the proximity by other two short level shifts, and an isolated outlier.
% Load airline data.
% 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960
y = [112 115 145 171 196 204 242 284 315 340 360 417 % Jan
118 126 150 180 196 188 233 277 301 318 342 391 % Feb
132 141 178 193 236 235 267 317 356 362 406 419 % Mar
129 135 163 181 235 227 269 313 348 348 396 461 % Apr
121 125 172 183 229 234 270 318 355 363 420 472 % May
135 149 178 218 243 264 315 374 422 435 472 535 % Jun
148 170 199 230 264 302 364 413 465 491 548 622 % Jul
148 170 199 242 272 293 347 405 467 505 559 606 % Aug
136 158 184 209 237 259 312 355 404 404 463 508 % Sep
119 133 162 191 211 229 274 306 347 359 407 461 % Oct
104 114 146 172 180 203 237 271 305 310 362 390 % Nov
118 140 166 194 201 229 278 306 336 337 405 432 ]; % Dec
y1=y(:);
y1(50:55)=y1(50:55)-300;
y1(68:end)=y1(68:end)-700;
y1(70:75)=y1(70:75)+300;
y1(90:90)=y1(90:90)+300;
% Create structure specifying model
model=struct;
model.trend=2; % quadratic trend
model.s=12; % monthly time series
model.seasonal=204; % number of harmonics
model.lshift=41:length(y1)-40; % position where monitoring level shift
model.X=[];
% Create structure lts specifying lts options
lshiftlocref=struct;
% Set window length for local refinement.
lshiftlocref.wlength=10;
% Set tuning constant to use inside Huber rho function
lshiftlocref.huberc=1.5;
close all
% Estimate the parameters
[out, varargout]=LTSts(y1,'model',model,'nsamp',500,...
'plots',2,'lshiftlocref',lshiftlocref,'msg',0);
% Using the notation of the paper RPRH: A=2, B=4, G=2 and $\delta_1>0$.
str=strcat('A=2, B=4, G=2, $\delta_2=',num2str(out.posLS),'$');
numpar = {'model parameters:' , str};
title(findobj('-regexp','Tag','LTSts:ts'),numpar,'interpreter','LaTeX','FontSize',16);
% generate the wedgeplot
% wedgeplot(out,'transpose',true,'extradata',[y1 out.yhat]);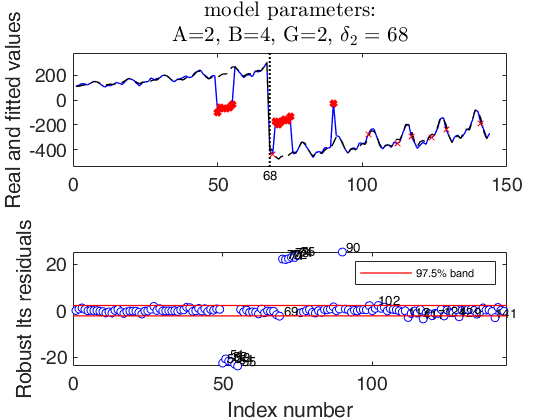
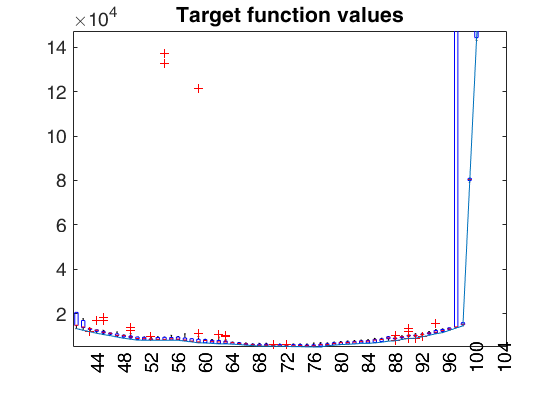
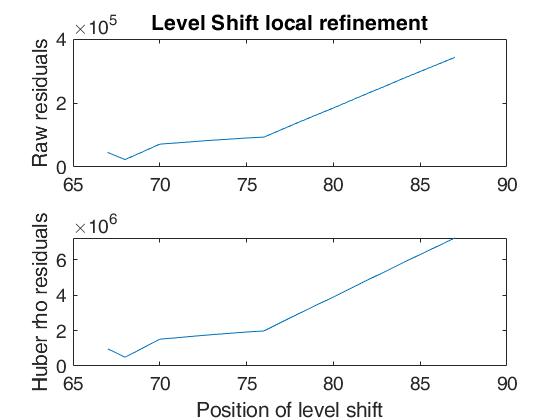
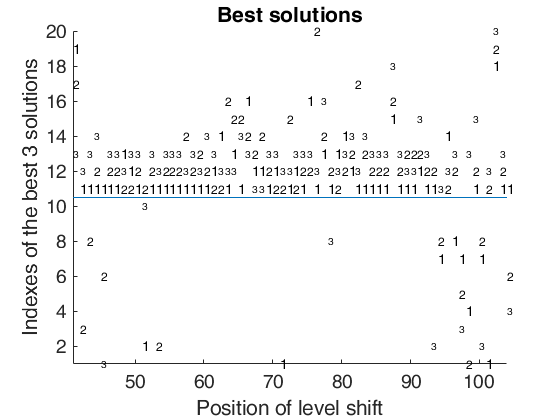
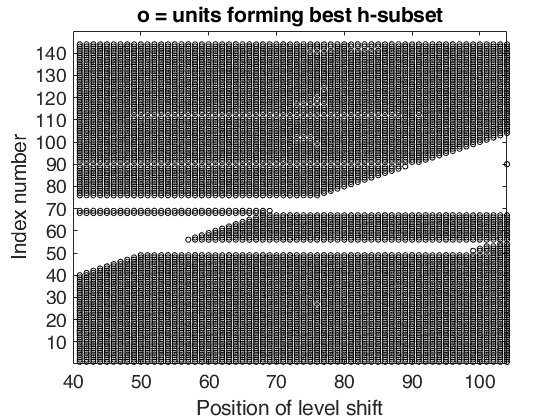
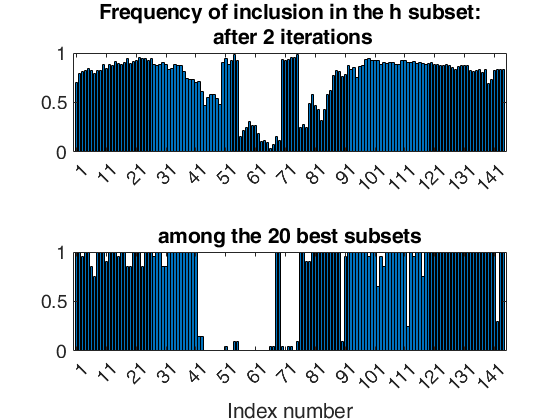
Examples 4 and 5 used in the paper RPRH: trade data.
Examples 4 and 5 used in the paper RPRH: trade data.
%% Examples 4 and 5 used in the paper RPRH: trade data.
close all; clear all;
% the datasets
load('TTP12119085');
load('TTP17049075');
Y4 = P12119085{:,1};
Y5 = P17049075{:,1};
% the model
model = struct;
model.trend = 1;
model.seasonal = 102;
model.s = 12;
model.lshift = 14:length(Y4)-13;
% LTSts
out4 = LTSts(Y4,'model',model,'plots',0,'dispresults',true,'msg',0);
out5 = LTSts(Y5,'model',model,'plots',0,'dispresults',true,'msg',0);
% the wedgeplot with the time series and the detected outliers and
% level shift
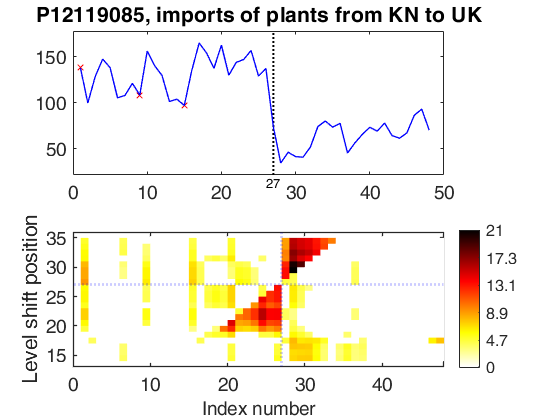
wedgeplot(out4,'extradata',Y4,'titl','P12119085, imports of plants from KN to UK');
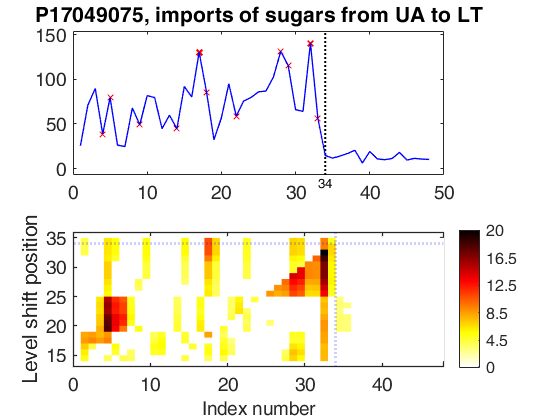
wedgeplot(out5,'extradata',Y5,'titl','P17049075, imports of sugars from UA to LT');
% Forecasts with a 99.9 per cent confidence level
nfore=10;
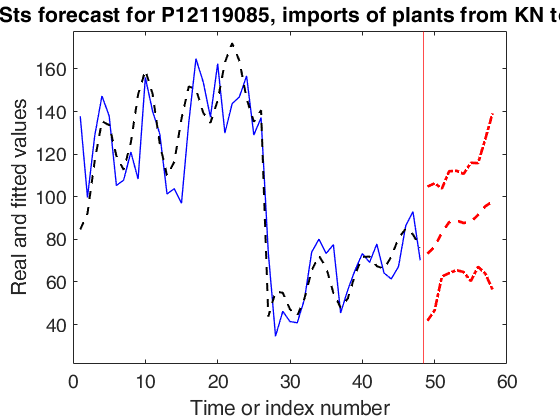
outfore4 = forecastTS(out4,'model',model,'nfore',nfore,'conflev',0.999,'titl','LTSts forecast for P12119085, imports of plants from KN to UK');
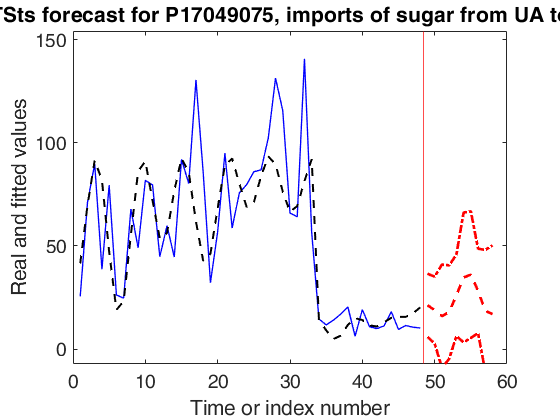
outfore5 = forecastTS(out5,'model',model,'nfore',nfore,'conflev',0.999,'titl','LTSts forecast for P17049075, imports of sugar from UA to LT');
% Comparing with FS (needs conflev option)
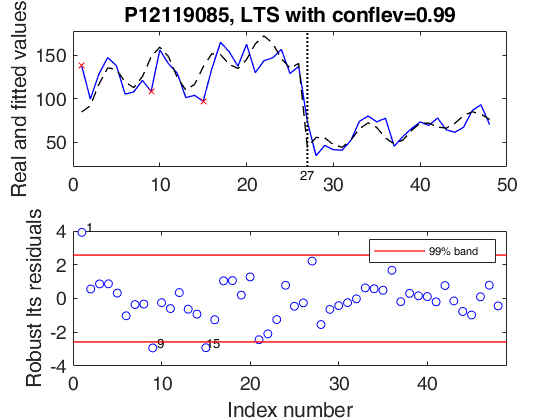
outLTS4 = LTSts(Y4,'model',model,'plots',1,'conflev',0.99,'msg',0);
drawnow;
ax = findall(0, 'Type', 'axes', 'Tag', 'LTSts:ts');
title(ax,'P12119085, LTS with conflev=0.99');
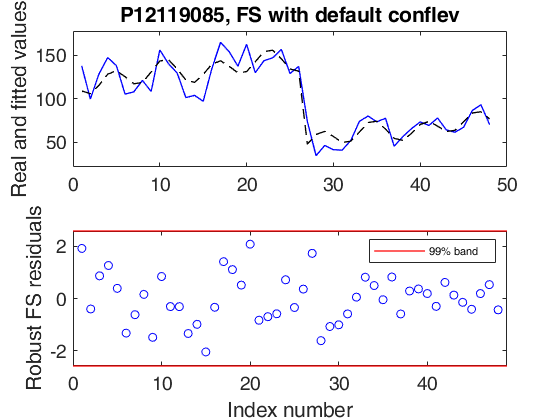
outFRS4 = FSRts(Y4,'model',model,'plots',1);
ax=findobj(gcf,'Tag','FSRts:ts');
title(ax,'P12119085, FS with default conflev');
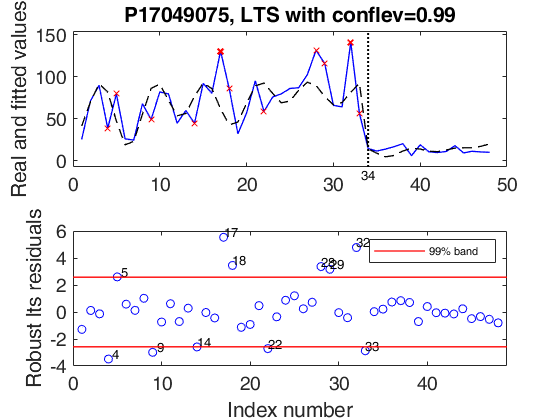
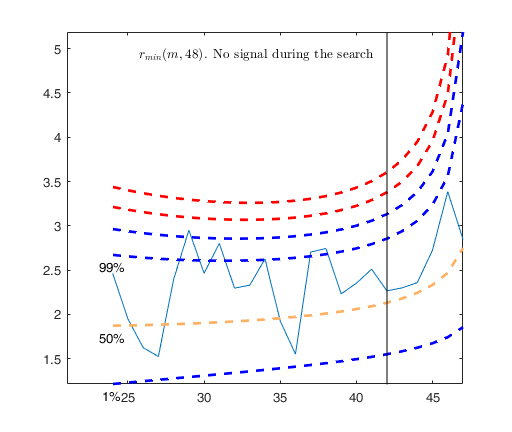
outLTS5 = LTSts(Y5,'model',model,'plots',1,'conflev',0.99,'msg',0);
ax=findobj(gcf,'Tag','LTSts:ts');
title(ax,'P17049075, LTS with conflev=0.99');
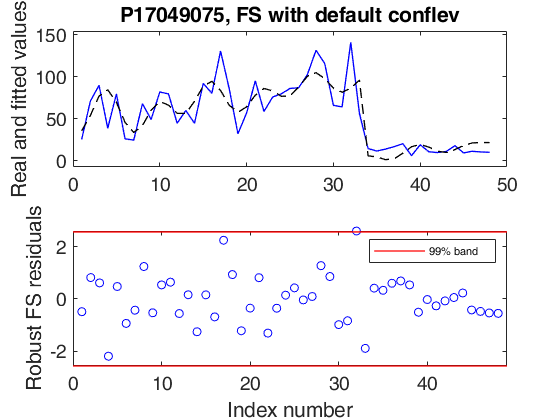
outFRS5 = FSRts(Y5,'model',model,'plots',1);
ax=findobj(gcf,'Tag','FSRts:ts');
title(ax,'P17049075, FS with default conflev'); Coeff SE t pval
_______ ____ ______ ____
b_trend1 115.27 4.51 25.59 0.00
b_trend2 1.59 0.27 5.80 0.00
b_cos1 -2.83 3.92 -0.72 0.47
b_sin1 -12.42 4.69 -2.65 0.01
b_cos2 -9.07 4.66 -1.95 0.06
b_sin2 -22.60 4.71 -4.80 0.00
b_varaml -0.02 0.00 -3.72 0.00
b_lshift -112.62 7.63 -14.76 0.00
Level shift position t=27
Coeff SE t pval
______ ____ ______ ____
b_trend1 55.14 3.85 14.30 0.00
b_trend2 0.90 0.20 4.52 0.00
b_cos1 15.54 4.15 3.75 0.00
b_sin1 3.61 4.27 0.85 0.40
b_cos2 -32.50 4.25 -7.64 0.00
b_sin2 -16.06 4.31 -3.72 0.00
b_varaml -0.02 0.00 -12.15 0.00
b_lshift -79.41 5.70 -13.94 0.00
Level shift position t=34
Level shift for t=14
Level shift for t=15
Level shift for t=16
Level shift for t=17
Level shift for t=18
Level shift for t=19
Level shift for t=20
Level shift for t=21
Level shift for t=22
Level shift for t=23
Level shift for t=24
Level shift for t=25
Level shift for t=26
Level shift for t=27
Level shift for t=28
Level shift for t=29
Level shift for t=30
Level shift for t=31
Level shift for t=32
Level shift for t=33
Level shift for t=34
Level shift for t=35
-------------------------
Signal detection loop
Sample seems homogeneous, no outlier has been found
Summary of the exceedances
1.00 99.00 999.00 9999.00 99999.00
1.00 2.00 0 0 0
Level shift for t=14
Level shift for t=15
Level shift for t=16
Level shift for t=17
Level shift for t=18
Level shift for t=19
Level shift for t=20
Level shift for t=21
Level shift for t=22
Level shift for t=23
Level shift for t=24
Level shift for t=25
Level shift for t=26
Level shift for t=27
Level shift for t=28
Level shift for t=29
Level shift for t=30
Level shift for t=31
Level shift for t=32
Level shift for t=33
Level shift for t=34
Level shift for t=35
-------------------------
Signal detection loop
Sample seems homogeneous, no outlier has been found
Summary of the exceedances
1.00 99.00 999.00 9999.00 99999.00
0 5.00 1.00 0 0
Input Arguments
Output Arguments
References
Rousseeuw, P.J., Perrotta D., Riani M. and Hubert, M. (2018), Robust Monitoring of Many Time Series with Application to Fraud Detection, "Econometrics and Statistics". [RPRH]