FSRaddt
FSRaddt produces t deletion tests for each explanatory variable.
Description
Examples
 FSRaddt with optional arguments.
FSRaddt with optional arguments.
FSRaddt with optional arguments.We perform a variable selection on the 'famous' stack loss data using different transformation scales for the response.
load('stack_loss');
y=stack_loss{:,4};
X=stack_loss{:,1:3};
%We start with a fan plot based on first-order model and the five most common values of $\lambda$ (Figure below).
[out]=FSRfan(y,X,'plots',1);
% The fan plot shows that the square root transformation, lambda= 0.5,
% is supported by all the data, with the absolute value of the statistic
% always less than 1.5. The evidence for all other transformations
% depends on which observations have been deleted: the log transformation
% is rejected when some of the suspected outliers are introduced into the
% data although it is acceptable for all the data: ?= 1 is rejected as
% soon as any of the suspected outliers are present.
%
% Given that the transformation for the response which is chosen
% depends on the number of units declared as outliers we perform a
% variable selection using the original scale, the square root and the
% log transformation.
% Robust variable selection using original
% untransformed values of the response
% Monitoring of deletion t stat in the original scale
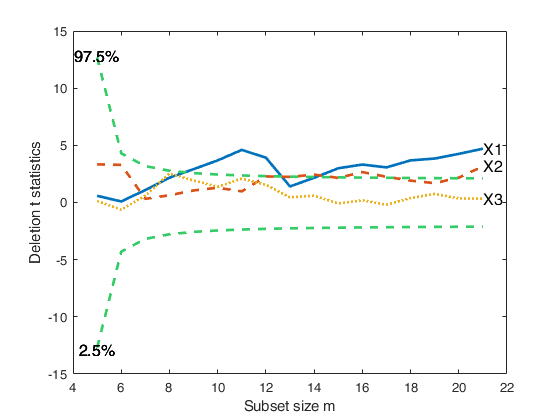
[out]=FSRaddt(y,X,'plots',1,'quant',[0.025 0.975],'nsamp',5000);
% Robust variable selection using square root values
% Monitoring of deletion t stat using transformed response based on the square root
[out]=FSRaddt(y.^0.5,X,'plots',1,'quant',[0.025 0.975]);
% Robust variable selection using log transformed values of the response
% Monitoring of deletion t stat using log transformed values
[out]=FSRaddt(log(y),X,'plots',1,'quant',[0.025 0.975]);
% Conclusion: the forward analysis based on the deletion t statistics
% clearly reveals that variable X3, independently from the transformation
% which is chosen and the number of outliers which are declared, is NOT
% significant.
Total estimated time to complete LMS: 0.00 seconds Total estimated time to complete LMS: 0.00 seconds Total estimated time to complete LMS: 0.00 seconds Total estimated time to complete LMS: 0.00 seconds Total estimated time to complete LMS: 0.00 seconds Number of subsets to extract greater than (n p). It is set to (n p) Total estimated time to complete LMS: 0.00 seconds Number of subsets to extract greater than (n p). It is set to (n p) Total estimated time to complete LMS: 0.00 seconds Number of subsets to extract greater than (n p). It is set to (n p) Total estimated time to complete LMS: 0.18 seconds ------------------------------ Warning: Number of subsets without full rank equal to 14.1% Total estimated time to complete LMS: 0.00 seconds Total estimated time to complete LMS: 0.00 seconds Total estimated time to complete LMS: 0.00 seconds ------------------------------ Warning: Number of subsets without full rank equal to 13.6% Total estimated time to complete LMS: 0.01 seconds Total estimated time to complete LMS: 0.00 seconds Total estimated time to complete LMS: 0.00 seconds ------------------------------ Warning: Number of subsets without full rank equal to 14.6%
Related Examples
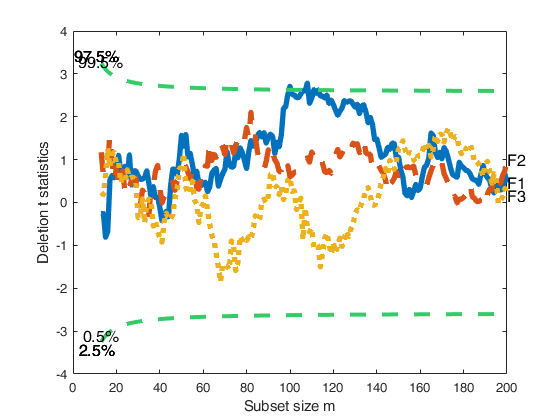
FSRaddt with labels for the columns of matrix X.
FSRaddt with labels for the columns of matrix X.Line width equal to 3 for the curves representing envelopes; line width equal to 4 for the curves associated with deletion t stat.
n=200;
p=3;
randn('state', 123456);
X=randn(n,p);
% Uncontaminated data
y=randn(n,1);
[out]=FSRaddt(y,X,'plots',1,'nameX',{'F1','F2','F3'},'lwdenv',3,'lwdt',4);
Total estimated time to complete LMS: 0.01 seconds Total estimated time to complete LMS: 0.01 seconds Total estimated time to complete LMS: 0.01 seconds
Input Arguments
Output Arguments
References
Atkinson, A.C. and Riani, M. (2002b), Forward search added variable t tests and the effect of masked outliers on model selection, "Biometrika", Vol. 89, pp. 939-946.