MixSim
MixSim generates k clusters in v dimensions with given overlap
Description
Examples
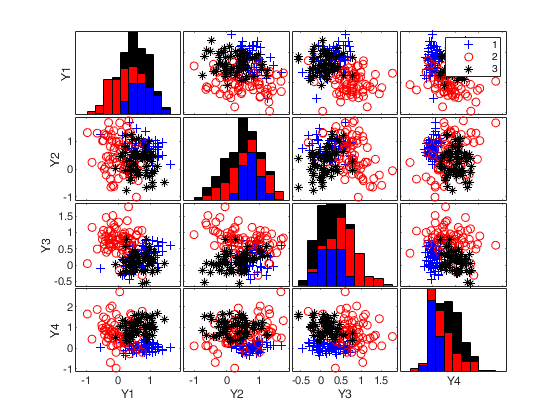
 Generate 3 groups in 4 dimensions.
Generate 3 groups in 4 dimensions.
Generate 3 groups in 4 dimensions.Use a maximum overlap equal to 0.15.
rng(10,'twister') out=MixSim(3,4) n=200; [X,id]=simdataset(n, out.Pi, out.Mu, out.S); spmplot(X,id)
out =
struct with fields:
OmegaMap: [3×3 double]
BarOmega: 0.09
MaxOmega: 0.15
StdOmega: 0.05
fail: 0
Pi: [3×1 double]
Mu: [3×4 double]
S: [4×4×3 double]
rcMax: [2×1 double]
ans(:,:,1) =
-1.00 33.03 36.03 39.02
30.03 -1.00 37.02 40.02
31.03 34.03 -1.00 41.02
32.03 35.03 38.02 -1.00
ans(:,:,2) =
-1.00 45.02 48.02 51.02
42.02 -1.00 49.02 52.02
43.02 46.02 -1.00 53.02
44.02 47.02 50.02 -1.00
ans(:,:,3) =
0 57.02 60.01 63.01
54.02 0 61.01 64.01
55.02 58.02 0 65.01
56.02 59.01 62.01 0
Related Examples
Input Arguments
Output Arguments
More About
References
Maitra, R. and Melnykov, V. (2010), Simulating data to study performance of finite mixture modeling and clustering algorithms, "The Journal of Computational and Graphical Statistics", Vol. 19, pp. 354-376. [to refer to this publication we will use "MM2010 JCGS"]
Melnykov, V., Chen, W.-C. and Maitra, R. (2012), MixSim: An R Package for Simulating Data to Study Performance of Clustering Algorithms, "Journal of Statistical Software", Vol. 51, pp. 1-25.
Davies, R. (1980), The distribution of a linear combination of chi-square random variables, "Applied Statistics", Vol. 29, pp. 323-333.
Garcia-Escudero, L.A., Gordaliza, A., Matran, C. and Mayo-Iscar, A. (2008), A General Trimming Approach to Robust Cluster Analysis. Annals of Statistics, Vol. 36, 1324-1345.
Riani, M., Cerioli, A., Perrotta, D. and Torti, F. (2015), Simulating mixtures of multivariate data with fixed cluster overlap in FSDA, "Advances in data analysis and classification", Vol. 9, pp. 461-481.
Parlett, B.N. and Reinsch, C. (1971), Balancing a Matrix for Calculation of Eigenvalues and Eigenvectors, in Bauer, F.L. Eds, "Handbook for Automatic Computation", Vol. 2, pp. 315-326, Springer.
See Also
tkmeans
|
tclust
|
tclustreg
|
lga
|
rlga
|
ncx2mixtcdf
|
restreigen